Qué sucede cuando un LLM 'piensa': Tokens, Logits y Sampling
Un análisis profundo de los tres conceptos fundamentales que explican el comportamiento de los LLMs: tokens, logits y estrategias de sampling.
Envías un prompt. El modelo “piensa” unos segundos. Y genera una respuesta que parece inteligente.
¿Qué ocurrió en ese tiempo?
Si tu forma de implementar sistemas con LLMs se basa en usar un framework de alto nivel más las APIs de OpenAI y derivados, probablemente no entiendes cómo funciona este proceso de “pensamiento”. Y está bien — las APIs están diseñadas precisamente para que no tengas que saberlo. Pero si quieres construir sistemas serios alrededor de LLMs, necesitas entender qué está pasando bajo el capó.
Porque cuando tu aplicación necesita que el modelo siempre genere JSON válido, o cuando quieres garantizar que nunca mencione información sensible, o cuando simplemente quieres entender por qué a veces “alucina” información… ahí es cuando “llamar a una API y esperar lo mejor” deja de ser suficiente.
La buena noticia es que esto no es magia. Es un proceso bastante elegante de matemáticas aplicadas y probabilidad. Y una vez que entiendes los tres conceptos fundamentales — tokens, logits y sampling — todo el comportamiento extraño de los LLMs empieza a tener sentido.
Las cajas negras
Si trabajas con LLMs hoy, parte de tu código probablemente se ve así:
import openai
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explica la computación cuántica"}]
)
print(response.choices[0].message.content)Funciona. Resuelve problemas. Pero es completamente opaco.
No sabes por qué el modelo:
- Genera formatos inconsistentes (a veces JSON válido, a veces no)
- Ocasionalmente “alucina” información falsa con absoluta confianza
- Se niega a responder ciertas preguntas pero no otras similares
- Produce resultados distintos cada vez (incluso con el mismo prompt)
Cuando algo falla, tu único recurso es ajustar el prompt y esperar que funcione mejor. Es debugging por ensayo y error.
El problema es que estas APIs están diseñadas precisamente para ocultar el proceso de generación. Solo ves la entrada y la salida final. Junto con lo que envías a la API, hay un conjunto de etiquetas y reglas adjuntas a tu prompt para controlar el comportamiento del modelo según los intereses y medidas de seguridad del proveedor — que no necesariamente están alineados con los tuyos y los objetivos de tu proyecto.
Para tener control real, necesitas entender qué ocurre en el medio. Y todo empieza con tres conceptos fundamentales.
Concepto 1: Tokens — el lenguaje real de los modelos
Los modelos de lenguaje no leen texto como nosotros. Leen números (más específicamente, vectores).
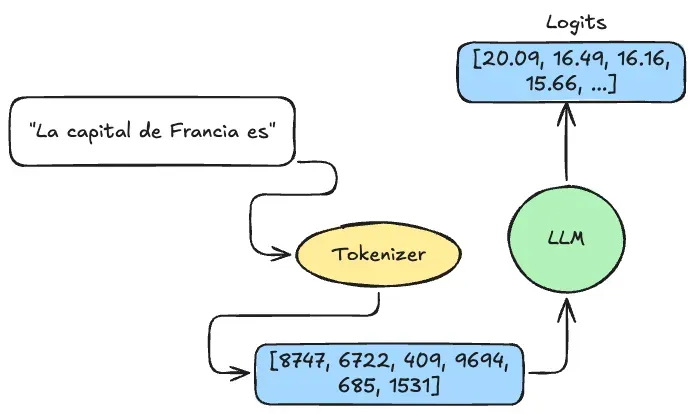
Cuando envías un prompt, lo primero que ocurre es que el texto se convierte en una secuencia de números llamados tokens. Este proceso lo hace un componente llamado tokenizador.
Prompt: "Hola, mundo!"
Tokens: [9707, 11, 1879, 0]Cada número representa un “fragmento” de texto del vocabulario del modelo. Los vocabularios típicos tienen entre 100,000 y 200,000 tokens distintos según el modelo (Qwen3, por ejemplo, tiene más de 150,000 tokens).
Detalle importante: El tokenizador y el modelo están íntimamente ligados. Un modelo solo puede procesar tokens generados por el mismo tokenizador que se usó durante su entrenamiento. No puedes intercambiarlos arbitrariamente.
¿Qué es exactamente un token?
No siempre es una palabra completa:
- La palabra “Ingeniero” podría ser 1 token o más, según el tokenizador
- “No lo sé” son típicamente varios tokens
- ”🤖” (emoji) podría ser 1 o más tokens
- Los espacios y signos de puntuación también son tokens
Por qué importa:
- Los límites de la ventana de contexto se miden en tokens, no en palabras. “Ventana de contexto máxima de 4,096” significa 4,096 tokens. En inglés, aproximadamente 1 token ≈ 0.75 palabras. En español o con código, la proporción cambia significativamente. Si el tokenizador se entrenó principalmente con texto en inglés, las palabras en español tienden a dividirse en más tokens (menos eficiente).
- Los tokens determinan lo que el modelo puede “entender”. Si una palabra poco común fue dividida en 5 tokens, el modelo tiene que reconstruir su significado a partir de esos fragmentos.
- Los costos de las APIs se calculan por token. Más tokens = más dinero. Los prompts concisos cuestan menos.
El modelo nunca ve tu texto original. Solo ve esa secuencia de números. Todo su “entendimiento” está basado en patrones que aprendió sobre cómo esos números se relacionan entre sí.
Concepto 2: Logits — las “opiniones” del modelo sobre lo que viene después
Una vez que el modelo procesa los tokens del prompt, genera algo llamado logits.
Los logits son un vector de números (puntuaciones) que representan “qué tan probable es que cada token del vocabulario sea el siguiente”. Si el vocabulario tiene 151,669 tokens (como en Qwen3), obtienes 151,669 puntuaciones.
Ejemplo real:
Imagina que el prompt es: “La capital de Francia es”
top_5_logits:
- token: "Par"
valor: 20.09
- token: "Paris"
valor: 16.49
- token: ":"
valor: 16.16
- token: "."
valor: 15.67
- token: "..."
valor: 15.67Los números aún no son probabilidades — son puntuaciones crudas:
- Puntuaciones altas (20.09) = tokens muy probables
- Puntuaciones bajas o negativas = tokens poco probables
De logits a probabilidades
Los logits se transforman en probabilidades usando una función matemática llamada softmax. Conceptualmente, softmax toma esas puntuaciones y las convierte en valores entre 0 y 1 que suman 1.
| Token | Logit | Probabilidad |
|---|---|---|
| ”Par” | 20.09 | 85% |
| “Paris” | 16.49 | 2% |
| ”:“ | 16.16 | 2% |
| ”.“ | 15.67 | 1% |
| ”…“ | 15.67 | 1% |
| (otros) | … | 9% |
¿Por qué “Par” tiene 85% mientras “Paris” solo 2%?
Porque el prompt está en español. El modelo detecta el idioma del contexto y ajusta sus predicciones en consecuencia. Como el tokenizador quizás no tiene un único token para “París” (con tilde), el modelo opta por una estrategia de fragmentación: genera “Par” primero, sabiendo que generará “ís” en la siguiente iteración para completar la palabra con acento.
Este es un ejemplo perfecto de cómo el modelo no solo “predice tokens” — adapta sus predicciones según el contexto lingüístico.
Nota: Los logits se calculan solo para la última posición de la secuencia. El modelo no predice toda la respuesta de una vez — solo el siguiente token. Este es el corazón del proceso autorregresivo.
Concepto 3: Sampling — cómo elegir el siguiente token
Ya tenemos probabilidades para cada token del vocabulario. Ahora viene la pregunta clave: ¿cómo elegimos cuál usar?
Aquí hay un detalle importante: el modelo no elige el siguiente token. El trabajo del modelo termina cuando genera los logits. Todo lo que viene después — convertir logits a probabilidades con softmax y elegir el siguiente token — es responsabilidad del sistema de inferencia.
Esta es una distinción crítica: puedes tomar el mismo modelo y cambiar completamente su comportamiento solo modificando la estrategia de sampling, sin tocar el modelo en absoluto.
Estrategia 1: Sampling greedy (temperatura = 0)
Siempre elegir el token con mayor probabilidad.
Características:
- Determinístico: Ejecuta el mismo prompt 100 veces y obtendrás exactamente la misma respuesta
- Seguro: Elige la opción “más correcta” según el modelo
- Ideal para: Generación de código, respuestas factuales, formatos estrictos (JSON, tablas)
Estrategia 2: Sampling aleatorio (temperatura > 0)
En lugar de elegir siempre el más probable, el modelo muestrea aleatoriamente según las probabilidades. Esto introduce variabilidad.
El parámetro de temperatura:
La temperatura modifica los logits antes de aplicar softmax:
logits_ajustados = logits / temperatura
probabilidades = softmax(logits_ajustados)| Temperatura | Comportamiento | Cuándo usar |
|---|---|---|
| 0.0 | Greedy: siempre elige el más probable | Código, datos, tareas precisas |
| 0.1 - 0.3 | Casi determinístico, variación mínima | Respuestas técnicas |
| 0.5 - 0.8 | Balance entre coherencia y creatividad | Conversaciones, escritura |
| 1.0 - 1.5 | Muy creativo, puede desviarse del tema | Brainstorming, ficción |
| 2.0+ | Caótico, frecuentemente incoherente | Experimentación |
Top-k sampling: limitar a los k más probables
Después de calcular probabilidades, solo se consideran los k tokens con mayor probabilidad y se descartan los demás.
- Ventaja: Previene la “basura” — los tokens muy improbables nunca aparecerán
- Desventaja: Rígido — siempre considera exactamente k tokens independientemente de la confianza del modelo
- Valores típicos: k=1 (greedy), k=40-50 (balanceado), k=100+ (permisivo)
Top-p sampling (nucleus sampling): límite adaptativo
En lugar de un número fijo de tokens, top-p incluye tokens hasta que la probabilidad acumulada alcance p (típicamente 0.9 o 0.95).
- Ventaja: Adaptativo — cuando el modelo está muy seguro (un token con 95%), el núcleo es pequeño. Cuando está indeciso, crece automáticamente.
- Valores típicos: p=0.9 (balanceado), p=0.95 (permisivo)
El orden de aplicación es:
- Aplicar temperatura a los logits
- Calcular softmax → probabilidades
- Aplicar top-k (si está configurado)
- Aplicar top-p (si está configurado)
- Re-normalizar
- Samplear
El bucle autorregresivo: generación token a token
La respuesta no se genera de una sola vez. Se construye token a token en un bucle.
El modelo transformer hace una sola cosa: dado un conjunto de tokens de entrada, produce logits para cada token del vocabulario. Es más un clasificador que un modelo “generativo” en el sentido tradicional. Todo lo demás — softmax, sampling, el bucle — es responsabilidad del sistema de inferencia.
# Iteración 1
input_tokens = tokenizer.encode("La capital de Francia es")
logits = model(input_tokens)
probs = softmax(logits / temperatura)
filtered_probs = apply_top_p(probs, p=0.9)
next_token = sample(filtered_probs) # ej. "Par"
input_tokens.append(next_token)
# Iteración 2
logits = model(input_tokens) # ahora incluye "Par"
# ... repetir hasta token de fin o longitud máximaPor qué esta distinción importa:
- La variabilidad viene del sampling, no del modelo. El modelo es determinístico (mismo input → mismos logits). Las respuestas distintas vienen del sampling aleatorio.
- Todo el control está en el sistema de inferencia. ¿Quieres forzar JSON válido? Modifica los logits antes del softmax. ¿Quieres prohibir tokens? Pon sus logits en -∞. El modelo no se toca.
- Por qué la generación tarda. Cada token requiere un forward pass completo del modelo — 200 tokens significa 200 forward passes. Eso es lo que consume tiempo y recursos.
Por qué se llama “autorregresivo”
Porque el sistema alimenta la salida del paso anterior como entrada del siguiente. El modelo simplemente clasifica cada vez que le preguntamos. Nosotros orquestamos el bucle.
Por qué todo esto importa en la práctica
Una vez que entiendes tokens, logits y sampling, varios comportamientos “misteriosos” de los LLMs empiezan a tener sentido:
- Formatos inconsistentes: El modelo clasifica tokens de forma independiente. No hay garantía de que la secuencia completa forme JSON válido — a menos que el sistema de inferencia lo fuerce (decodificación restringida).
- Alucinaciones: El modelo no “sabe” hechos — aprendió qué tokens suelen seguir a otros. Si vio más frecuentemente “El CEO de Apple es Steve Jobs” que información actualizada, repite ese patrón.
- Repetición de frases: Si el contexto forma un patrón repetitivo, el modelo predecirá consistentemente que el patrón debe continuar. Solución: penalización por repetición (modificar los logits de tokens usados recientemente).
- Sensibilidad al prompt: Cada cambio de texto modifica los tokens de entrada, lo que cambia las distribuciones de logits. Esas distribuciones distintas llevan a caminos de sampling diferentes.
- Latencia y costo: El cuello de botella es el forward pass del modelo. El sistema de inferencia (softmax, sampling) es barato. Las APIs cobran por token porque cada token = un forward pass.
La diferencia entre usar y dominar
Si solo usas LLMs a través de APIs, todo esto es interesante pero no esencial. Las APIs abstraen estos detalles con buena razón.
Pero si quieres:
- Controlar exactamente lo que el sistema genera — prohibir tokens, forzar formatos, garantizar consistencia
- Depurar comportamientos extraños — analizar el contexto y los logits en lugar de ajustar prompts a ciegas
- Optimizar latencia y costo — entender dónde cortar sin perder calidad
- Construir sistemas predecibles en producción — “funciona el 95% del tiempo” no es suficiente
- Adaptar el comportamiento sin reentrenar — estrategias de sampling personalizadas, procesadores de logits dinámicos
…entonces necesitas entender este proceso en profundidad.
La diferencia entre “usar un LLM” y “construir sistemas con LLMs” está en cuánto control tienes sobre cada componente: tokenización, el forward pass del modelo, modificación de logits, sampling y la orquestación del bucle.
Las APIs te dan el resultado final. Entender el proceso te da las herramientas para controlar ese resultado.