
5 Días Construyendo un Sistema OCR Distribuido: Event Driven Architecture en la Práctica
Así que me propuse un reto: construir un sistema de OCR distribuido. Subes un PDF, el sistema lo procesa en paralelo y te devuelve el texto extraído. Nada revolucionario. Pero hacerlo bien.

Llevaba meses hablando de Event Driven Architecture y Microservicios. Dando opiniones. Criticando implementaciones ajenas. Pero como decimos en la industria “Hablar es barato, show me the code.”
He construido sistemas “Semi EDA” para varias empresas, proyectos híbridos con arquitecturas mixtas. Pero todo en repositorios privados, invisible para el resto del mundo.
Decidí que era hora de cambiar eso. Construir algo público, funcional, que no se quedara en teoría ni en slides de PowerPoint. Un proyecto “de juguete” lo suficientemente serio como para demostrar patrones reales.
Así que me propuse un reto: construir un sistema de OCR distribuido. Subes un PDF, el sistema lo procesa en paralelo y te devuelve el texto extraído. Nada revolucionario. Pero hacerlo bien (escalable, resiliente, observable) resultó ser un viaje fascinante por todo lo que está mal (y bien) con los sistemas distribuidos modernos.
El resultado es EDA Workshop: 5 microservicios (yo les llamo nanoservicios), NATS JetStream, Postgres, Kubernetes, y suficiente complejidad operativa como para cuestionar todas mis decisiones de vida.
Este no es un tutorial paso a paso. Es la historia honesta de cómo lo construí, las decisiones que tomé, las que me arrepiento, y las herramientas que salvaron mi cordura.
Episodio 0: El Infierno del “Localhost”
Antes de escribir una línea de lógica de negocio, me topé con el verdadero enemigo de los microservicios: el entorno de desarrollo local.
¿Cómo ejecutas 5 servicios de Go, Postgres, NATS, S3, y mantienes tu laptop sin explotar? Si tu respuesta es “10 pestañas de terminal con go run”, déjame ahorrarte tiempo: no funciona. No a largo plazo.
La Solución: Tilt
Terminé usando Tilt. No es sexy. No tiene una página de marketing con gradientes violetas y promesas de “10x developer productivity”. Es solo una herramienta que funciona.
Tilt observa tu código, reconstruye solo lo que cambió, y actualiza los contenedores en Kubernetes local (uso k3d) en segundos. Los logs de todos los servicios en una ventana. Las dependencias bien definidas (no levantes el backend hasta que Postgres esté listo).
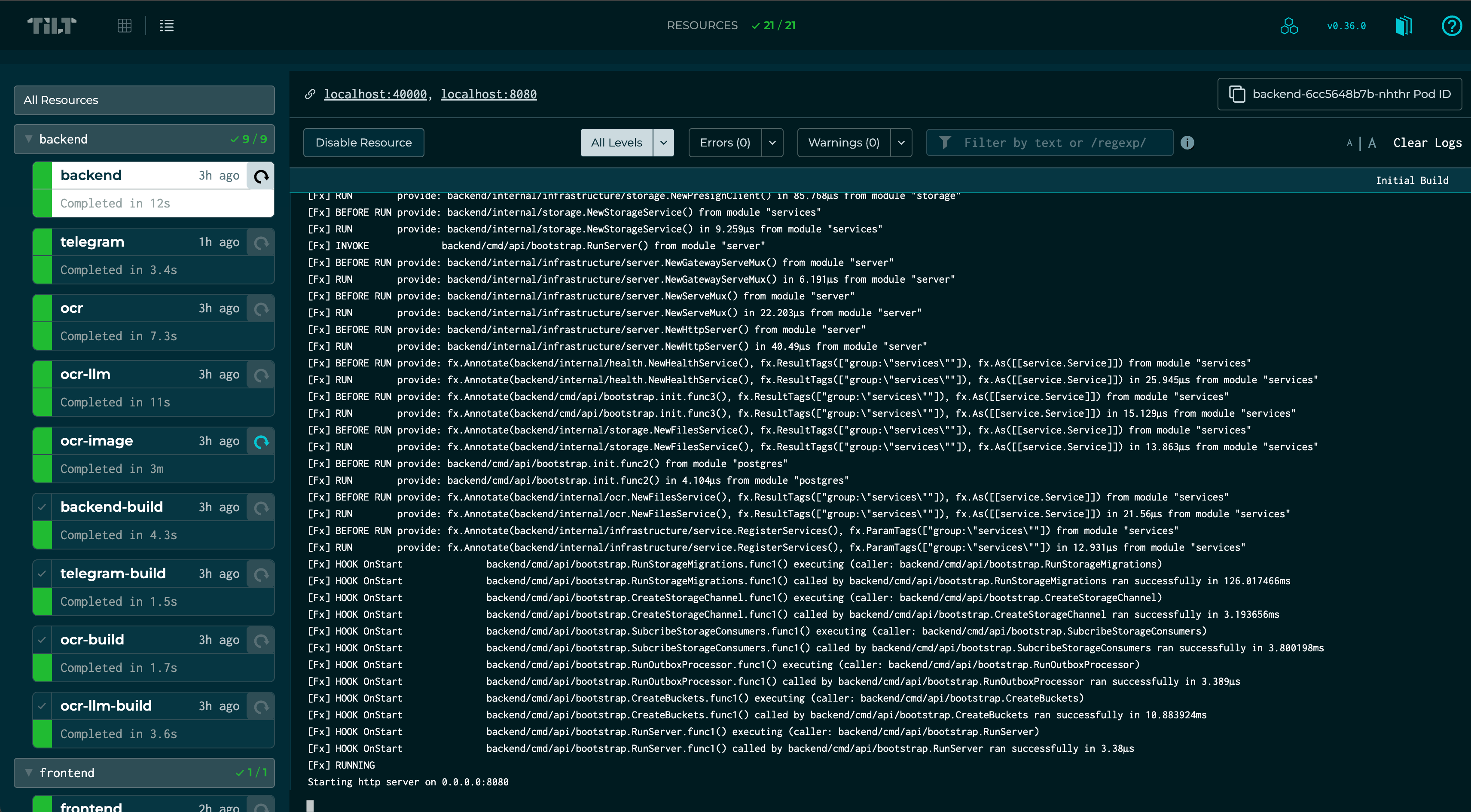
La parte honesta: Tilt tiene una curva de aprendizaje. Kubernetes local puede ser pesado. Pero una vez configurado, el “inner loop” (código → build → test) es increíblemente rápido. Cambio una función en el código, Tilt recompila, actualiza el pod, y veo el resultado en menos de 5 segundos.
¿Vale la pena? Si vas a tener más de 3 servicios, absolutamente.
Episodio 1: El Broker que No Quería Usar (NATS JetStream)
Necesitaba un message broker. Mi primera opción fue Kafka porque “es lo que usan las empresas grandes”.
Luego recordé que Kafka requiere ZooKeeper (o KRaft), consume RAM como si estuviera en oferta, y tiene una curva de aprendizaje más empinada que aprender Haskell. Para este proyecto de OCR, era como usar un bulldozer para plantar una flor.
Así que elegí NATS JetStream por razones pragmáticas:
1. Es un binario único de ~30MB. No necesita Java, no necesita ZooKeeper, no necesita sacrificios a los dioses de la JVM.
2. JetStream agrega persistencia al core de NATS. Los mensajes sobreviven reinicios, los consumers pueden hacer replay, y tiene delivery guarantees decentes.
3. Creé algunas capas de abstracción para facilitarme la vida.
La Abstracción que Salvó mi Sanidad
Para no repetir código de suscripción en cada servicio, creé un NatsConsumer[T] genérico. Define tu handler, pasa el tipo de evento, y el consumer maneja todo el resto (ACKs, retries, graceful shutdown, worker pools).
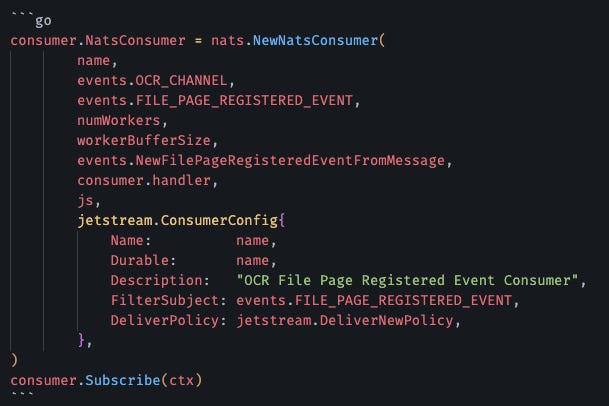
La parte triste: NATS es genial para casos de uso como este. Pero si necesitas exact-once delivery o particionamiento complejo como Kafka, estás frito. JetStream tiene at-least-once, lo que significa que tu código debe ser idempotente. Si no sabes qué significa eso, aprende antes de usar cualquier message broker.
Episodio 2: El Contrato Sagrado (Protobuf o el Caos)
En sistemas distribuidos, JSON es el equivalente a programar sin tests: funciona hasta que no funciona.
Un servicio envía user_id, otro espera userId. Boom. Runtime error en producción.
Decidí que todo se comunica con Protocol Buffers. No negociable.
Buf: Protoc con Esteroides
Usar protoc directamente es como cocinar con utensilios oxidados. Funciona, pero sufres. Buf es la versión moderna:
1. Linting estricto: Si rompo compatibilidad backward, Buf me grita antes del commit.
2. Generación unificada: Un solo comando genera código Go, documentación OpenAPI, y hasta TypeScript para el frontend (buscar heyapi.dev)
3. Registro remoto: Puedes publicar tus schemas y compartirlos entre equipos.
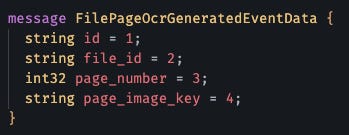
Ejecuto buf generate y obtengo:
- Structs de Go con validación
- Swagger docs
La parte aburrida: Protobuf agrega fricción inicial. Tienes que aprender la sintaxis, configurar Buf, y convencer a tu equipo de que “no, JSON no es suficiente”. Pero el día que haces un cambio breaking y el compilador te avisa antes de que llegue a producción, entiendes por qué existe.
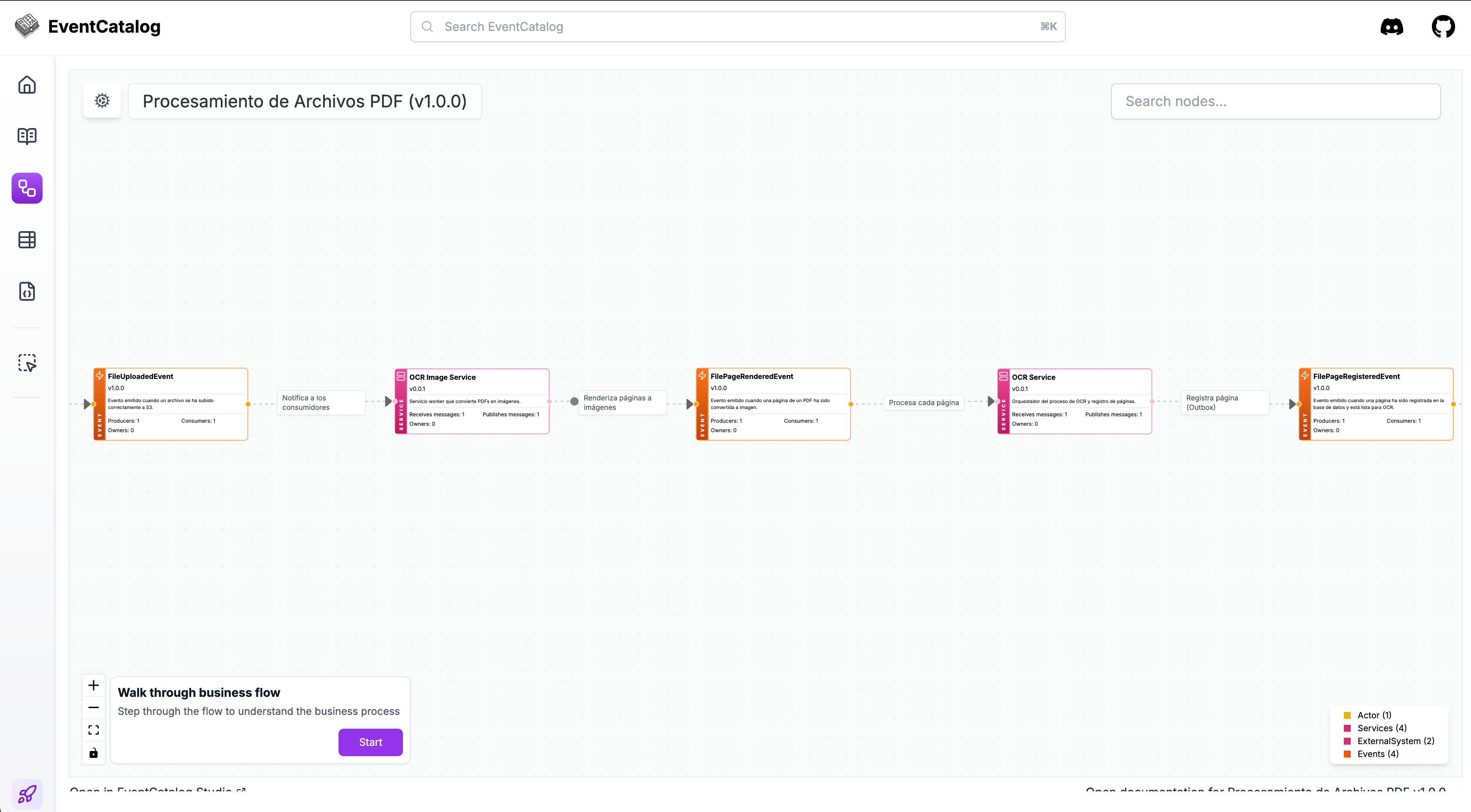
Episodio 3: Fan-Out (o Cómo un Evento Dispara Múltiples Cosas)
Aquí es donde EDA empieza a brillar de verdad.
Cuando un usuario sube un archivo, publico un FileUploadedEvent. ¿Quién lo consume?
1. Storage Consumer: Guarda metadata en Postgres.
2. OCR Image Service: Descarga el PDF y lo convierte en imágenes.
3. Audit Service (futuro): Registra quién subió qué.
Ninguno de estos servicios sabe de la existencia del otro. El Storage Service no tiene idea de que hay un OCR downstream. Solo dice: “Archivo subido. Háganle lo que quieran.”
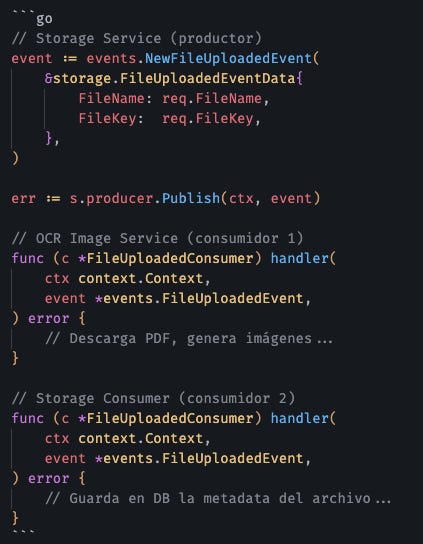
Escalabilidad gratis: Si suben 100 PDFs, se pueden levantar más pods en Kubernetes (usando HPA) de ocr-image, NATS reparte la carga, y el sistema no suda.
La parte difícil: Fan-out es poderoso, pero puede convertirse en caos si no documentas qué servicios escuchan qué eventos. Por eso usé EventCatalog para documentar cada evento, sus productores y consumidores. Sin documentación, un año después nadie recuerda por qué el servicio X escucha el evento Y.
Episodio 4: El Fantasma de la Inconsistencia (Outbox Pattern al Rescate)
Aquí es donde los sistemas distribuidos te patean en la cara.
El OCR Service necesita:
1. Guardar en Postgres que la página X está lista.
2. Publicar un evento FilePageRegisteredEvent para que el LLM Service la procese.
Si hago esto en dos pasos separados, tengo un problema:
- Guardo en DB, falla NATS → Inconsistencia. La DB dice “listo”, pero nadie se enteró.
- Publico en NATS, falla la DB → Inconsistencia. El evento se disparó, pero no hay registro.
Transactional Outbox Pattern
La solución: guardar el evento en una tabla outbox_events dentro de la misma transacción de la base de datos.
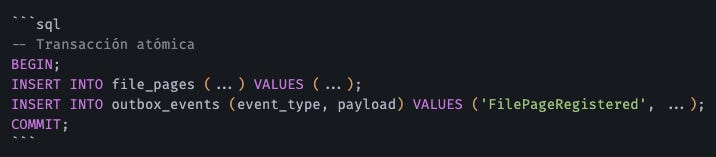
Luego, un proceso background (OutboxProcessor) lee la tabla y publica en NATS de forma segura.
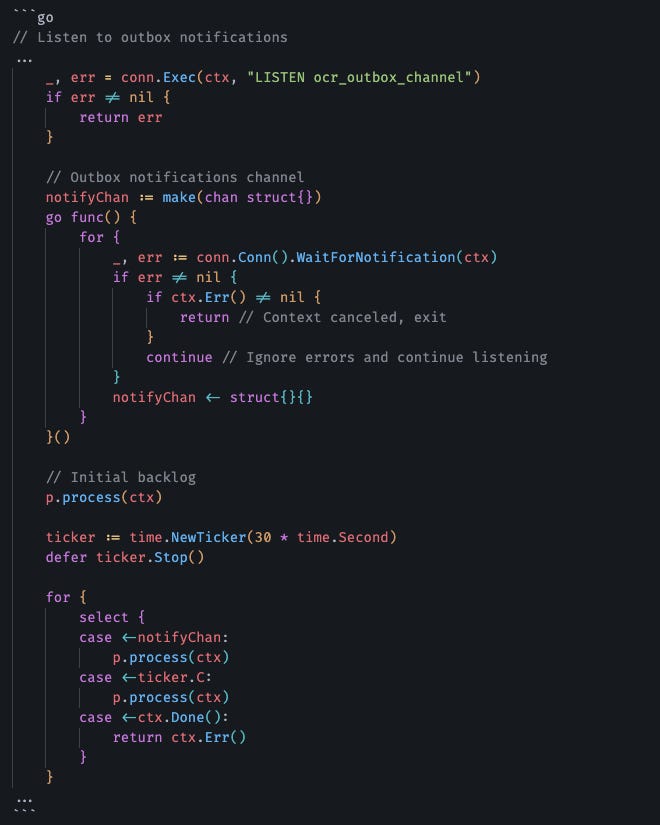
LISTEN/NOTIFY: Latencia Casi Cero
Para que no se sienta lento, uso LISTEN/NOTIFY de Postgres. La DB notifica al proceso Go instantáneamente cuando hay un nuevo evento en la tabla. No polling cada 5 segundos como un animal.
Si dejé un pull cada 30 segundos como una medida de seguridad. Digamos que fallan al publicarse los eventos en NATS. El pull a los 30 segundos volverá a reintentar la operación de publicar los eventos. Sin esa red de seguridad los eventos que fallan solo serían reintentados cuando se publicaran nuevos eventos en la tabla de outbox.
The hardcore: El Outbox Pattern es la solución correcta para este problema. Pero agrega complejidad. Tienes que gestionar la tabla, limpiar eventos antiguos, y monitorear que el processor no se caiga. Si tu sistema puede vivir con inconsistencia eventual (ej. analytics), quizás no lo necesites. Para OCR, donde cada página cuenta, no es negociable.
Episodio 5: ORMs son una Mentira (SQLC al Rescate)
Necesitaba ejecutar transacciones SQL “complejas”. Mi primera opción fue GORM porque “todos lo usan”.
Luego entendí por qué los ORMs son la deuda técnica que todos esconden bajo la alfombra: prometen abstraer SQL, pero terminás peleando con dos lenguajes a la vez. Cuando algo falla, estás debuggeando queries autogeneradas que parecen escritas por alguien que nunca vio un EXPLAIN. Y cuando necesitás optimizar, descubres que el ORM te obligó a cargar 47 objetos relacionados para obtener un solo campo.
El problema no es que los ORMs sean malos per se, el problema es que resuelven un problema que no tienes (escribir SQL básico) creando tres que sí vas a tener (N+1 queries, performance impredecible, y debugging kafkiano).
Usé SQLC en su lugar.
SQLC No es un ORM. Es un Compilador.
Escribes SQL crudo:
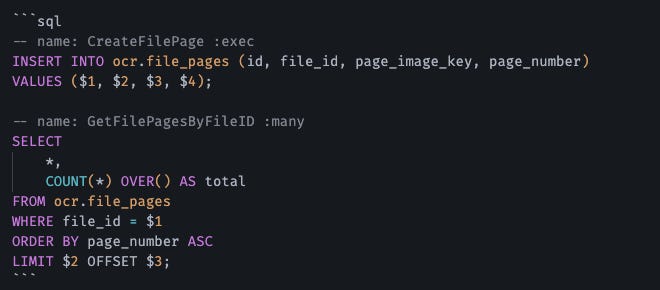
SQLC genera código Go con type-safety:
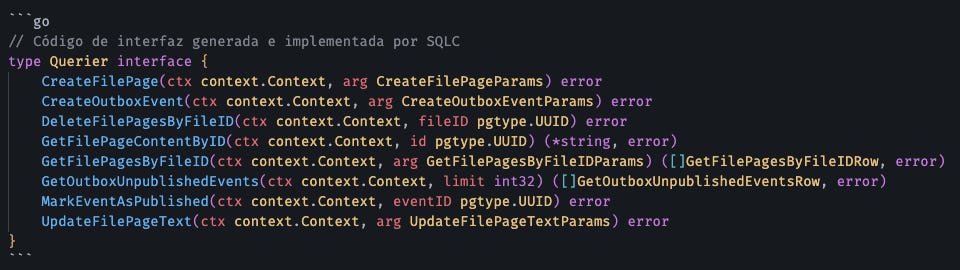
La parte que a algunos no les gusta: SQLC requiere que realmente conozcas SQL. No te salva de escribir queries malas. Pero si sabes SQL (y deberías), es infinitamente mejor que cualquier ORM que hayas usado.
Episodio 6: Migraciones sin Dolor (golang-migrate)
Los schemas de base de datos evolucionan. Gestionar esto con “ejecuta este script en producción” es una receta para ser despedido.
Usé golang-migrate. Cada cambio es un par de archivos versionados:
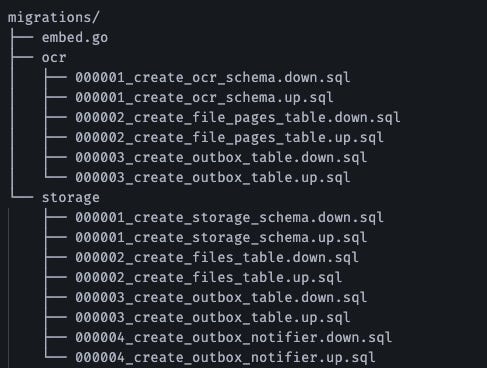
Mi aplicación ejecuta las migraciones automáticamente al iniciar. Local, staging, y producción siempre están sincronizados. Si algo sale mal, puedo hacer rollback con un comando.
Meh: Esto es básico, no debería ser notable. Pero he visto suficientes equipos ejecutando scripts SQL manualmente como para saber que no es obvio para todos.
Episodio 7: gRPC por Dentro, REST por Fuera (gRPC-Gateway)
Me gusta definir mis apis usando gRPC porque es rápido, agnóstico del lenguaje y fuertemente tipado. Pero el frontend (React) y clientes externos hablan HTTP/JSON.
Mantener dos APIs separadas es doloroso y propenso a desincronización. Para eso está gRPC-Gateway.
Agrego anotaciones a mis archivos Protobuf:
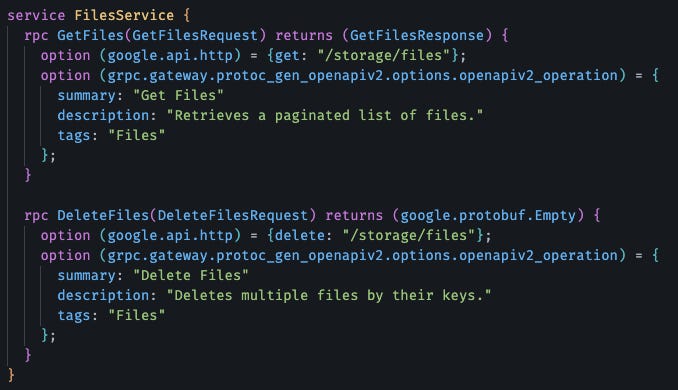
gRPC-Gateway genera un proxy HTTP que traduce JSON a llamadas gRPC. Una sola definición, dos interfaces.
La cruda realidad: gRPC-Gateway funciona bien para casos simples, pero si tienes necesidades HTTP complejas (file uploads multipart, SSE, websockets), vas a sufrir. Para mi caso de uso, es perfecto. La subida de archivos la maneja S3 directamente, el storage service solo se encarga de generar presigned URLs, y el resto son endpoints simples. En otra iteración de este proyecto trabajaré con streams para mantener al frontend informado del progreso del OCR en near real-time.
Episodio 8: Observabilidad (Porque Todo Va a Fallar)
En un monolito, debuggeas con breakpoints. En microservicios, debuggeas con trazas distribuidas.
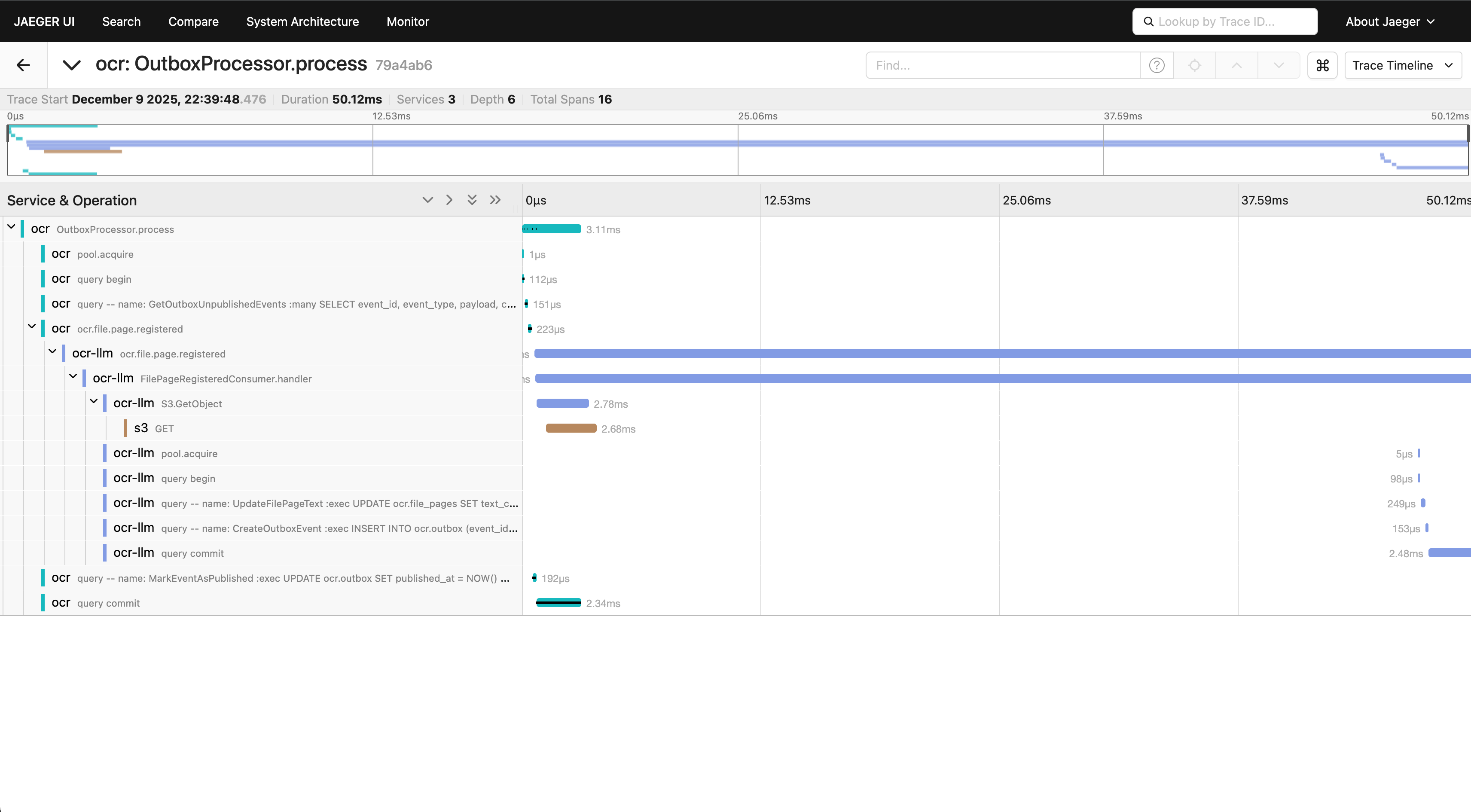
Integré OpenTelemetry desde el día 0. Cada operación genera un Span, y cuando un mensaje viaja por NATS, el contexto de tracing va con él.
El resultado en Jaeger es hermoso: puedo ver exactamente cuánto tardó S3, cuánto tardó Postgres, cuánto tardó el LLM, todo en una timeline continua.
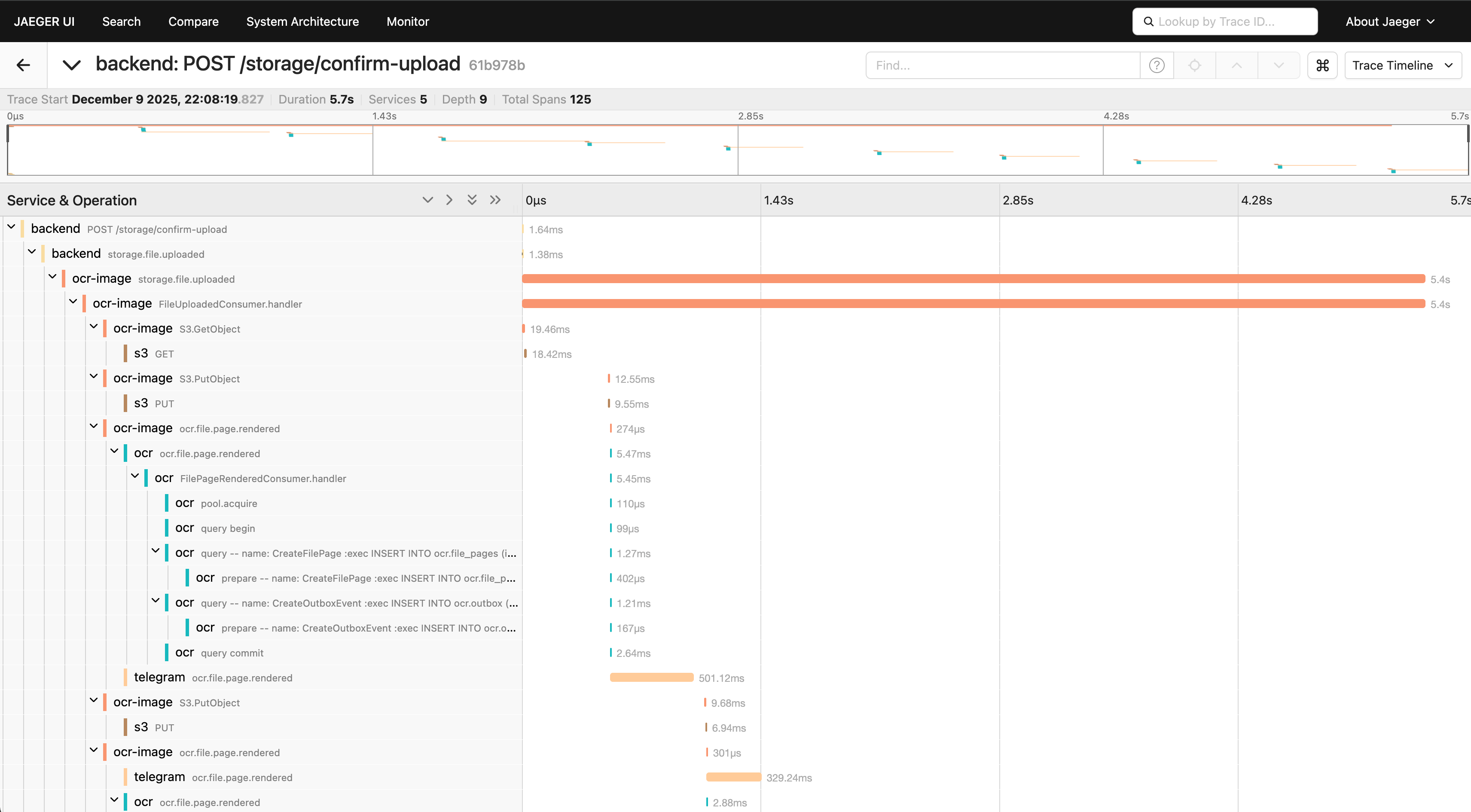
El dolor de cabeza: Configurar OpenTelemetry es un dolor. La documentación es densa, hay 50 formas de hacer la misma cosa, y vas a pasar un día entero haciendo que funcione. Pero una vez que funciona, debuggear se vuelve exponencialmente más fácil.
Por “suerte” todo el código de este proyecto es público así que no te tienes que romper la cabeza configurando opentelemetry, simplemente puedes copiar lo que implementé. Aunque si recomiendo estudiar que hay debajo del capó.
Conclusiones para pensar antes de dormir
¿Vale la pena toda esta complejidad?
Depende. 😎
Si estás construyendo un CRUD simple con 3 endpoints, no. Usa Rails o Django, despliega en Render, y vete a casa temprano.
Si estás construyendo algo que necesita escalar independientemente por partes, que tiene flujos asíncronos largos, o que evoluciona rápido con equipos distribuidos... entonces sí. EDA y microservicios tienen sentido.
Pero no te engañes: no es gratis. Pagas con complejidad operativa, curva de aprendizaje, y más cosas que pueden romperse.
Este proyecto, EDA Workshop, es mi intento de mostrar esa realidad. No es un tutorial color de rosa. Es un sistema real, con decisiones reales, y las herramientas que me salvaron de volverme loco.
Si te interesa ver el código, romperlo, o copiar patrones para tu propio proyecto, está todo en GitHub. Open source, sin paywall, y sin slides de marketing.
Repositorio: https://github.com/luiscib3r/eda-workshop
Y la próxima vez que alguien te venda “Arquitectura Agéntica Revolucionaria powered by IA”, pregúntales si implementaron el Outbox Pattern. Si te miran confundidos, sabes que es humo. 😉