
How to build a RAG System Locally
Building a RAG System Locally using Ollama and PostgreSQL with PgVector


What is a RAG system?
A Retrieval-Augmented Generation (RAG) system combines the capabilities of a large language model with a retrieval component that can fetch relevant documents or passages from a corpus. This powerful combination allows the language model to generate fluent and informed responses by not only relying on its trained knowledge, but also retrieving and referring to factual information from the supplied documents.
How it work?
A RAG system is composed of two main components: a retrieval engine and a large language model.
First, when a user provides a query or prompt to the system, the retrieval engine searches through a corpus (collection) of documents to find relevant passages or information related to the query. This is typically done using semantic search or vector similarity techniques to rank the documents based on their relevance to the query.
The top-ranked documents are then formatted into a context window or memory that can be consumed by the large language model. This context window provides the language model with relevant background information and facts from the retrieved documents.
Next, the language model takes the user's original query along with the context window as input. By combining its own trained knowledge with the supplementary information from the retrieved documents, the language model can generate a fluent and informative response to the query.
The generated response draws upon both the language model's understanding of the query topic and the factual details found in the relevant documents. This allows the system to provide comprehensive answers that not only leverage the model's capabilities but also incorporate specific evidence and data from the corpus.
Finally, the system outputs the language model's generated response as the final answer to the user's original query.
Why build a RAG locally?
Having a RAG system running locally is beneficial for several reasons. First, it allows you to experiment and tinker with the system within your own environment, without relying on external services or APIs. This can be particularly useful for testing, debugging, or customizing the system to meet specific requirements. Additionally, a local RAG system can provide improved privacy and data security, as sensitive information remains within your controlled infrastructure. Furthermore, running the system locally can offer potential performance advantages, reducing latency and eliminating dependence on external network conditions.
Let's get started!
To build the RAG system locally, as mentioned earlier, we need two main components: a Large Language Model (LLM) and a retrieval engine. Our first step is setting up an LLM to run on our local machine.
The LLM
We are building this system on a personal computer or basic workstation, so we need an LLM model that is relatively lightweight in terms of resource requirements. To accomplish this, we will be using Ollama.
While Ollama can leverage GPU acceleration, it doesn't strictly necessitate specialized GPUs designed for deep learning workloads. This makes Ollama an ideal choice for our local RAG system, as it can run efficiently without demanding high-end hardware.
Ollama is an advanced AI tool that allows users to run large language models (LLMs) locally on their computers. It simplifies the process of running language models locally, providing users with greater control and flexibility in their AI projects. Ollama supports a variety of models, including Llama 2, Mistral, and other large language models. Users can leverage Ollama to personalize and create language models according to their preferences, making it accessible to researchers, developers, and anyone interested in exploring the potential of large language models without relying on cloud-based platforms.
To get started with Ollama, head over to their website at
and follow the provided instructions to install and set up the LLM on your local machine. The process is straightforward and very easy to complete.
PostgreSQL as a Vector Database
For our vector storage needs, we'll be utilizing PostgreSQL along with the pgvector extension. PgVector is an open-source extension for PostgreSQL that enables us to store and search over machine learning-generated embeddings efficiently. It extends PostgreSQL's capabilities to handle vector data types and perform vector similarity searches.
Why a Vector Database?
At the core of a RAG system lies the ability to quickly retrieve relevant documents or passages from a corpus based on a given input query. This retrieval process is facilitated by techniques like semantic search, which involve mapping the query and documents into high-dimensional vector representations called embeddings.
Essentially, when a user provides a query to our RAG system, we can convert that query into an embedding vector. We can then use our vector database to quickly find the document embeddings that are most similar or "nearest neighbors" to the query embedding. This allows us to retrieve the most topically relevant documents or passages to augment our language model's response accurately.
So while the language model itself is a key component, the vector database working behind the scenes is equally vital. It provides the contextual retrieval mechanisms that elevate a RAG system's responses beyond just the model's trained knowledge.
Setting Up PostgreSQL with pgvector
To get started, make a new directory with any name you prefer for storing the project files.
Since we'll be using PostgreSQL with the pgvector extension as our vector database, we need to set up the database server. To simplify this process, we'll leverage Docker Compose.
First, create a new file named docker-compose.yml in your project directory with the following content:

This Docker Compose file sets up a PostgreSQL service using the pgvector/pgvector:pg16 image, which includes the pgvector extension pre-installed. It also maps a host port to the container's PostgreSQL port and creates a named volume for persisting data.
Next, create a .env file in the same directory with the following content:

This .env file contains the configuration details for our PostgreSQL instance, such as the database name, user credentials, and port number. The Docker Compose file reads these values from the .env file, allowing easy configuration management.
With these files in place, you can start the PostgreSQL server by running the following command in your project directory:
docker-compose up -dThis will spin up the PostgreSQL container based on the provided configuration. You can then connect to the database using your preferred client or directly within your application code.
Feel free to modify the .env file if you prefer different database names or credentials. Additionally, you can customize the Docker Compose file further if needed, such as mapping different ports or adjusting resource limits.
With the necessary infrastructure in place, we are now ready to dive into the code and bring our local RAG system to life.
Installing and importing libraries
For setting up my environment, I prefer to use pipenv, but you can opt for pip, poetry, or any other tool of your choice. First, let's create a new pipenv environment. I'll be using Python 3.12 for this project.
pipenv --python 3.12Now we can proceed to install the required packages within the newly created virtual environment:
pipenv install langchain langchain-community wikipedia python-dotenv pgvector psycopg2-binaryBegin by creating a new Python file (e.g., main.py) or a Jupyter Notebook in your project directory. We'll need to import the required libraries and set up our environment variables that we defined previously on our .env file.

The purpose of each imported library will become apparent as we progress through the subsequent steps and utilize their respective functionalities.
Let's define a function to construct the connection string for our PostgreSQL database, and also set up two simple variables for configuring our Ollama models: one for the LLM and another for the model we want to use for generating embeddings.
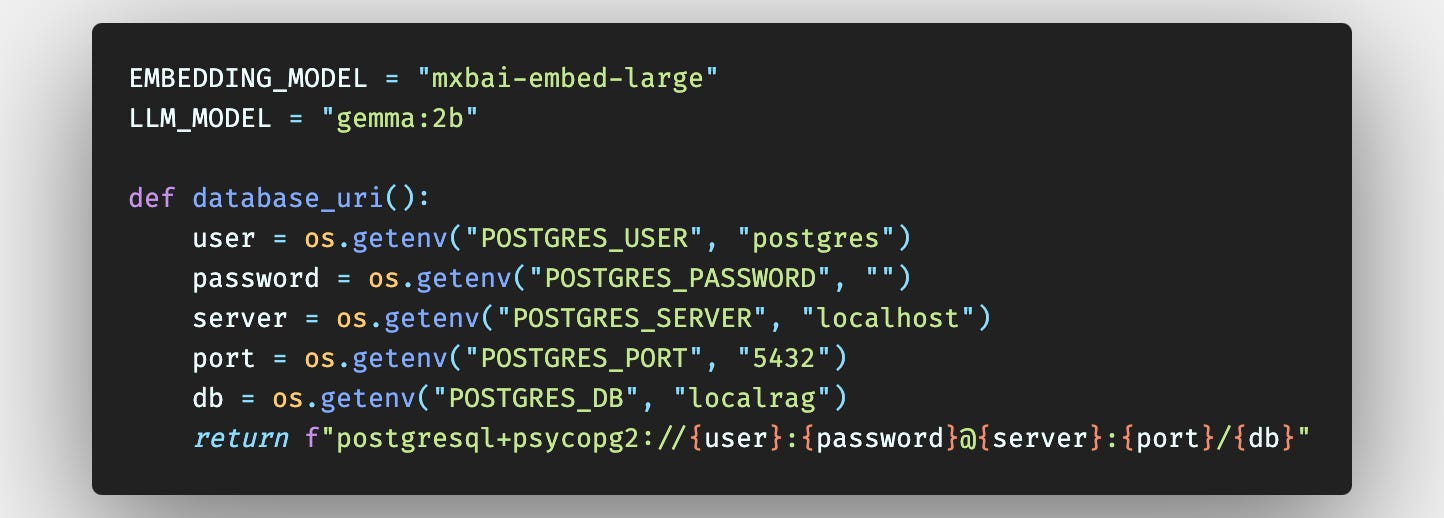
In this section, we're setting up two variables to configure our LLM and the model we'll use for generating embeddings.
First, we define EMBEDDING_MODEL = "mxbai-embed-large". This variable specifies the model we'll use for creating vector embeddings of our documents. In this case, I've chosen the mxbai-embed-large model, but feel free to choose a different model that better suits your needs.
Next, we have LLM_MODEL = "gemma:2b". This variable represents the actual LLM model we'll be using for our RAG system. Here, I've opted for the gemma:2b model, but again, you can choose a different LLM model based on your requirements.
It's worth noting that while you can use an LLM model for generating embeddings, it may be inefficient and wasteful of resources, as LLM models tend to have more parameters and are generally slower for this specific task compared to dedicated embedding models.
Moving on, we define the database_uri function. This function constructs the connection string for our PostgreSQL database by retrieving the necessary environment variables (POSTGRES_USER, POSTGRES_PASSWORD, POSTGRES_SERVER, POSTGRES_PORT, and POSTGRES_DB) from the .env file we set up earlier. If any of these environment variables are not found, it provides default values. Finally, the function returns the properly formatted connection string using an f-string.
Instantiating the Core Components
It's time to instantiate the core components that will power our local RAG system. These components include the embedding model, vector database, retriever, and language model.

Embedding Model:
We create an instance of
OllamaEmbeddingsusing theEMBEDDING_MODELvariable we defined earlier. This object will be responsible for generating vector embeddings from text using the specified embedding model.Vector Database:
Next, we instantiate the
PGVectorclass, which serves as our vector database interface. We pass three arguments:embedding_function=embeddings: Theembeddingsobject we just created, which will be used to generate embeddings for storing in the database.connection_string=database_uri(): The connection string for our PostgreSQL database, obtained from thedatabase_urifunction.pre_delete_collection=True: This argument tells thePGVectorinstance to delete any existing collection before creating a new one, ensuring a clean slate. However, this option should not be used in a production environment, as it would result in data loss. We're using it here solely for the purpose of having a clean development environment.
Retriever:
We create a
retrieverobject by calling theas_retrievermethod on ourvector_dbinstance. This retriever will be responsible for performing similarity searches in the vector database to find the most relevant documents or passages based on a given query.Language Model:
Finally, we instantiate the
Ollamaclass, passing theLLM_MODELvariable as the model parameter. This object represents our Large Language Model, which will be used to generate natural language responses based on the retrieved information from the vector database.With these components in place, we can now proceed to integrate them and build the complete RAG system pipeline.
Chaining Together the RAG Components
In this section, we're building the pipeline or chain that orchestrates the various components of our RAG system. This pipeline will take a user's question as input and generate a concise answer by leveraging the retriever, language model, and the retrieved context.

First, we define a
human_promptstring that outlines the instructions for our question-answering assistant. This prompt informs the assistant to use the retrieved context to answer the given question. It also provides guidelines like using a maximum of three sentences and keeping the answer concise. The prompt includes placeholders for{context}and{question}, which will be filled dynamically during runtime. You can modify this prompt according to your requirements, such as changing the guidelines for answer length or adding additional instructions for the assistant.Next, we create a
promptobject usingChatPromptTemplate.from_messages. This prompt object will be used to format the input for our language model.Then, we construct the
rag_chainpipeline using LangChain's composition. The pipeline consists of the following components:{"context": retriever, "question": RunnablePassthrough()}: This dictionary maps the"context"key to ourretrieverobject, which will fetch relevant documents from the vector database based on the input question. The"question"key is mapped toRunnablePassthrough, which allows the input question to be passed through unmodified.| prompt: The retrieved context and the input question are piped into thepromptobject we created earlier. This formats the input according to the specified instructions.| llm: The formatted input is then piped into ourllmobject, which is theOllamalanguage model instance. The language model will generate a response based on the provided context and question.| StrOutputParser(): Finally, the output from the language model is passed through theStrOutputParser, which ensures that the output is returned as a string.
By constructing this
rag_chainpipeline, we've effectively connected all the core components of our RAG system. When a user provides a question, the pipeline will retrieve relevant context from the vector database, format the input, pass it to the language model for response generation, and return the final answer.This modular approach allows us to easily modify or extend the pipeline by adding or rearranging components as needed, while leveraging the power of LangChain's composition utilities.
Testing the RAG System
Now that we have our
rag_chainpipeline ready, it's time to perform some tests to evaluate the performance of our local RAG system. We'll provide sample queries and analyze the generated responses to ensure that our system is functioning as expected.


In this code, we have the wikipedia_query function, which takes a query string as input. It uses the WikipediaLoader to fetch up to three documents related to the query, splits the documents into smaller chunks using RecursiveCharacterTextSplitter, and adds these chunks to our vector database using vector_db.add_documents.
We then test our RAG system by invoking the wikipedia_query function with two different queries: "Transformer Architecture" and "Langchain". After loading the relevant documents into the vector database, we call rag_chain.invoke with specific questions about the Transformer paper and LangChain, respectively.
These examples utilize Wikipedia documents for testing, you should aim to use your own domain-specific documents or corpus, such as PDFs, raw text from chat logs, or any other relevant sources of information tailored to your use case. The Wikipedia tests serve as a starting point, but for a more comprehensive evaluation, it's recommended to load and index your actual documents into the vector database.
That's a Wrap, Folks!
If you'd like to explore a more comprehensive implementation of this local RAG system, including a functional API, feel free to check out my GitHub repository: https://github.com/luiscib3r/LLM-Projects/tree/main/local-rag. You'll find a Jupyter Notebook showcasing the complete code, as well as an API implementation for easy integration.
I encourage you to clone the repository, experiment with the code, and provide any feedback or comments you might have. If you have specific questions or would like me to delve deeper into certain topics related to RAG systems or any other aspect of this project, please don't hesitate to reach out. Your input and suggestions are invaluable in helping me improve and expand upon this content.