
Qué Pasa Cuando un LLM "Piensa": Tokens, Logits, y Sampling
Del prompt al primer token generado: el proceso que las APIs esconden y los AI Engineers necesitan entender.

Envías un prompt. El modelo “piensa” unos segundos. Y genera una respuesta que parece inteligente.
¿Qué pasó en ese tiempo?
Si tu manera de implementar sistemas con LLMs está basado en usar un framework de alto nivel más APIs de OpenAI y derivados tal vez no entiendas como funciona este proceso de “pensamiento”. Y está bien, las APIs están diseñadas precisamente para que no tengas que saber. Pero si quieres construir sistemas serios alrededor de LLMs, necesitas entender qué está pasando debajo del capó.
Porque cuando tu aplicación necesita que el modelo genere JSON válido siempre, o cuando quieres garantizar que nunca mencione información sensible, o cuando simplemente quieres entender por qué a veces “alucina” información... ahí es cuando “llamar a una API y esperar lo mejor” deja de ser suficiente.
La buena noticia es que esto no es magia. Es un proceso bastante elegante de matemática aplicada y probabilidad. Y una vez que entiendes los tres conceptos fundamentales (tokens, logits, y sampling), todo el comportamiento extraño de los LLMs empieza a tener sentido.
Las cajas negras
Si trabajas con LLMs hoy, probablemente parte de tu código se ve así:
Funciona. Resuelve problemas. Pero es completamente opaco.
No sabes por qué el modelo:
Genera formatos inconsistentes (a veces JSON válido, a veces no)
Ocasionalmente “alucina” información falsa con confianza absoluta
Se niega a responder ciertas preguntas pero no otras similares
Produce resultados diferentes cada vez (incluso con el mismo prompt)
Cuando algo falla, tu única herramienta es ajustar el prompt y esperar que funcione mejor. Es debugging por prueba y error.
El problema es que estas APIs están diseñadas precisamente para ocultar el proceso de generación. Solo ves el input y el output final. Ni siquiera vez realmente qué prompt se le está pasando al modelo. Junto con lo que tu le envías a la API hay un conjunto de etiquetas y reglas que se le adjuntan a tu prompt para controlar el comportamiento del modelo acorde a los intereses y las medidas del seguridad del proveedor, los cuáles no necesariamente están alineados con los tuyos y el objetivo de tú proyecto.
Para tener control real, necesitas entender qué pasa en el medio. Y todo comienza con tres conceptos fundamentales.
Concepto 1: Tokens (el lenguaje real de los modelos)
Los modelos de lenguaje no leen texto como nosotros. Leen números (siendo más específicos serían vectores).
Cuando envías un prompt, lo primero que sucede es que el texto se convierte en una secuencia de números llamados tokens. Este proceso lo hace un componente llamado tokenizer (o tokenizador).

Cada número representa un “pedazo” de texto del vocabulario del modelo. Los vocabularios típicos tienen entre 100,000 y 200,000 tokens diferentes, dependiendo del modelo (por ejemplo, Qwen3 tiene más de 150,000 tokens en su vocabulario).
Detalle importante: El tokenizer y el modelo están íntimamente ligados. Aunque técnicamente son componentes separados, un modelo solo puede procesar tokens generados por el mismo tokenizer que se usó durante su entrenamiento. No puedes intercambiarlos arbitrariamente. Si el modelo fue entrenado con el tokenizer de Qwen3, debes usar ese tokenizer específico para la inferencia. Cambiar de tokenizer rompería completamente la comprensión del modelo, porque los IDs de tokens no coincidirían con lo que aprendió.
¿Qué es exactamente un token?
No siempre es una palabra completa:
La palabra “Ingeniero” podría ser 1 token o 3, dependiendo del tokenizer
“I’m” típicamente son 2 tokens: “I” y “’m”
“🤖” (emoji) podría ser 1 o más tokens según el modelo
Espacios y signos de puntuación también son tokens
Por qué esto importa:
Los límites de la ventana de contexto se miden en tokens, no en palabras. Cuando un modelo dice “ventana de contexto máximo de 4,096”, son 4,096 tokens, no palabras. En inglés, aproximadamente 1 token ≈ 0.75 palabras.
En español o código, la relación cambia significativamente. Esto depende de cuánto texto en ese idioma o tipo de contenido vio el tokenizer durante su entrenamiento. Si el tokenizer fue entrenado principalmente con texto en inglés, las palabras en español tienden a dividirse en más tokens (menos eficiente). Lo mismo con código: si el tokenizer vio mucho Python, las palabras clave como
deforeturnprobablemente sean un solo token, pero sintaxis de lenguajes menos comunes puede fragmentarse en varios.(Si quieres entender a fondo cómo se construyen los tokenizers y por qué esto importa, Andrej Karpathy tiene un video excelente explicándolo: Let’s build the GPT Tokenizer. Cubriremos más sobre tokenizers en artículos futuros.)
Los tokens determinan qué puede “entender” el modelo. Si una palabra rara fue dividida en 5 tokens por el tokenizer, el modelo tiene que “reconstruir” su significado a partir de esas piezas.
El costo de las APIs se calcula por token. Más tokens = más dinero. Por eso los prompts concisos cuestan menos.
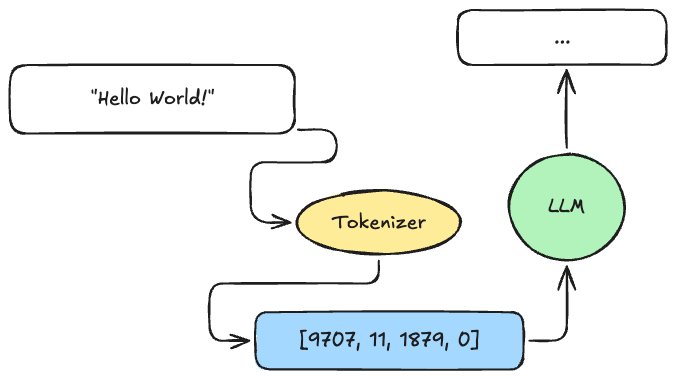
El modelo nunca ve tu texto original. Solo ve esa secuencia de números. Todo su "entendimiento" está basado en patrones que aprendió sobre cómo esos números se relacionan entre sí.
Concepto 2: Logits (las "opiniones" del modelo sobre qué sigue)
Una vez que el modelo procesa los tokens del prompt, genera algo llamado logits.
Los logits son un vector de números (scores) que representan “qué tan probable es que cada token del vocabulario sea el siguiente”.
Si el vocabulario tiene 151,669 tokens (como en Qwen3), obtienes 151,669 scores.
Ejemplo real con un modelo local:
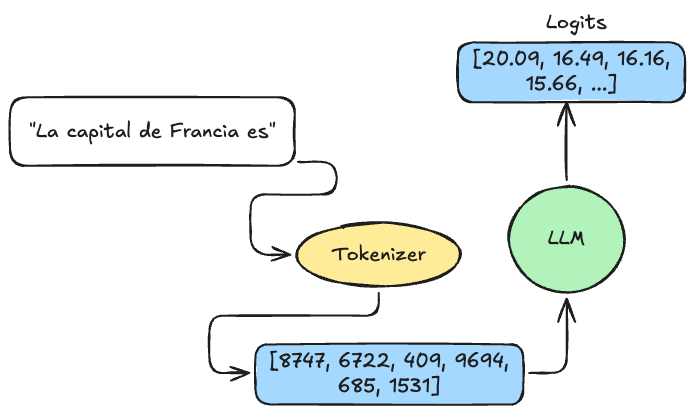
Imagina que el prompt es: “La capital de Francia es”

Los números no son probabilidades todavía, son scores sin procesar. Pero la intuición es clara:
Scores altos (20.09) = tokens muy probables
Scores bajos o negativos = tokens improbables
Observaciones interesantes de este ejemplo:
1. El modelo considera múltiples formas de generar la misma respuesta:
“Par” (fragmento que requiere un segundo token para completar “París”)
“Paris” (palabra completa)
Esto muestra cómo el tokenizer fragmentó las posibles respuestas, y el modelo evalúa cada variante.
2. Aparecen tokens de formato además del contenido:
Los dos puntos (”:”) tienen scores altos porque el modelo probablemente vio muchos ejemplos como “La capital de Francia es: París” en su entrenamiento.
Los puntos suspensivos (”...”) sugieren que el modelo también considera respuestas más narrativas.
3. Los scores no están normalizados:
El 20.09 vs 16.49 muestra preferencia relativa, pero no puedes interpretarlos como porcentajes directamente.
Para eso necesitamos el siguiente paso: convertirlos en probabilidades.
De logits a probabilidades
Los logits se transforman en probabilidades usando una función matemática llamada softmax. No necesitas entender la matemática detrás, solo el concepto: softmax toma esos scores y los convierte en valores entre 0 y 1 que al sumarlos todos el resultado es 1 (probabilidades reales).
Esto es fascinante por varias razones:
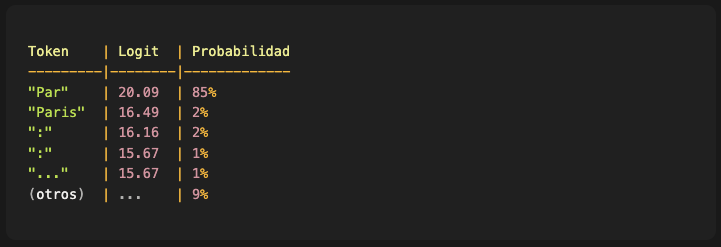
1. El contexto del prompt afecta las probabilidades:
“Par” tiene 85% de probabilidad, mientras que “Paris” solo 2%. ¿Por qué tanta diferencia?
Porque nuestro prompt está en español. El modelo detecta el idioma del contexto (”La capital de Francia es”) y ajusta sus predicciones en consecuencia. Como el vocabulario del tokenizer no tiene un token único para “París” (con tilde), el modelo opta por la estrategia de fragmentación: genera “Par” primero, sabiendo que en la siguiente iteración generará “ís” para completar la palabra correctamente acentuada.
Si el prompt hubiera estado en inglés (”The capital of France is”), probablemente “Paris” (sin tilde, un solo token) tendría la probabilidad más alta.
Este es un ejemplo perfecto de cómo el modelo no solo “predice tokens”, sino que adapta sus predicciones según el contexto lingüístico.
2. La diferencia entre logits se amplifica en probabilidades:
Entre “Par” (20.09) y “Paris” (16.49) hay solo ~3.6 puntos de diferencia en los logits crudos, pero al aplicar softmax, “Par” termina siendo 42.5 veces más probable (85% vs 2%).
Softmax exagera las diferencias relativas. Por eso pequeños cambios en los logits pueden tener efectos dramáticos en qué token se elige finalmente. Esto también explica por qué la temperatura (que veremos en la siguiente sección) tiene tanto impacto: modificar los logits antes del softmax cambia radicalmente la distribución de probabilidades.
3. La fragmentación de tokens es una estrategia, no un error:
“Par” es solo un fragmento de palabra. El modelo necesitará ejecutar otra iteración para generar “ís” y completar “París”.
Esto puede parecer ineficiente, pero es consecuencia directa de cómo se construyó el tokenizer. Si el vocabulario tiene tokens para palabras comunes en inglés pero no para todas las variantes acentuadas del español, el modelo trabaja con lo que tiene disponible.
Y lo interesante es que el modelo aprendió a manejar esta fragmentación correctamente. Sabe que después de “Par” en este contexto, debe venir “ís”, no cualquier otra continuación.
4. Artefactos del entrenamiento aparecen en los logits:
Los dos puntos (”:”) tienen 2% de probabilidad. Esto sugiere que durante el entrenamiento, el modelo vio muchos ejemplos con formato tipo:
"La capital de Francia es: París"
Estos patrones de formato (que probablemente vienen de Wikipedia, libros de texto, o contenido estructurado) dejan huellas en las probabilidades. El modelo considera esos formatos como opciones válidas, aunque en una conversación natural serían menos apropiados.
Estos son los “artefactos” del dataset de entrenamiento manifestándose en la generación.
Detalle técnico importante:
Los logits se calculan solo para la última posición de la secuencia. El modelo no está prediciendo toda la respuesta de una vez, sino únicamente el siguiente token. Este es el corazón del proceso autoregresivo que veremos más adelante.
Concepto 3: Sampling (cómo elegir el siguiente token)
Ya tenemos probabilidades para cada token del vocabulario. Ahora viene la pregunta clave: ¿cómo se elige cuál usar?
Aquí hay un detalle importante: el modelo no elige el siguiente token. De hecho, el trabajo del modelo termina cuando genera los logits. Todo lo que viene después (convertir logits en probabilidades con softmax, y elegir el siguiente token) es responsabilidad del sistema de inferencia, no del modelo en sí.
Esta distinción importa porque significa que puedes tomar el mismo modelo y cambiar completamente su comportamiento solo modificando la estrategia de sampling, sin tocar el modelo para nada.
El sampling (muestreo) es el proceso de elegir un token específico a partir de la distribución de probabilidades. Y aquí es donde tienes control real sobre el comportamiento del sistema.
Estrategia 1: Greedy sampling (temperatura = 0)
La estrategia más simple: siempre elegir el token con la probabilidad más alta.
En nuestro ejemplo anterior:

Características:
Determinístico: Ejecutas el mismo prompt 100 veces y obtienes exactamente la misma respuesta
Seguro: Elige la opción “más correcta” según el modelo
Predecible: Ideal cuando necesitas consistencia absoluta
Cuándo usarlo:
Generación de código (quieres el código más probable, no variaciones creativas)
Respuestas factuales (”¿Cuál es la capital de Francia?” debe dar siempre la misma respuesta)
Formatos estrictos (JSON, tablas, datos estructurados)
Estrategia 2: Random sampling (temperatura > 0)
En lugar de elegir siempre el más probable, el modelo samplea aleatoriamente según las probabilidades.
Esto introduce variabilidad. Ejecutas el mismo prompt 10 veces y obtienes 10 respuestas diferentes (aunque en nuestro ejemplo “Par” aparecerá en la mayoría porque tiene la probabilidad más alta).
El parámetro temperatura: tu control principal
La temperatura modifica los logits antes de aplicar softmax, lo que cambia radicalmente la distribución de probabilidades resultante.
Cómo funciona (conceptualmente):
Temperatura = 1.0: Usa las probabilidades tal cual (85%, 2%, 2%, etc.)
Temperatura < 1.0: “Aplana” las diferencias, hace la distribución más uniforme
Temperatura > 1.0: “Exagera” las diferencias, hace al líder aún más dominante

Cómo funciona (técnicamente):
Antes de aplicar softmax, los logits se dividen por la temperatura:

Efecto de diferentes temperaturas:
Temperatura = 1.0 (neutral):
No modifica los logits
Usa las probabilidades tal cual las calculó el modelo
Baseline de referencia
Temperatura < 1.0 (más confiado):
Divide logits por un número menor a 1 (equivale a multiplicarlos)
Exagera las diferencias entre logits
Después del softmax: el token líder domina aún más
Ejemplo: 85% → 95%, tokens raros casi desaparecen
Temperatura > 1.0 (más explorador):
Divide logits por un número mayor a 1 (los hace más pequeños)
Aplana las diferencias entre logits
Después del softmax: distribución más uniforme
Ejemplo: 85% → 60%, tokens raros ganan probabilidad
Temperatura → 0 (greedy):
Las diferencias se vuelven infinitas
Un solo token tiene 100% de probabilidad
Determinístico
En la práctica no podemos dividir por cero pero si podemos asignar un valor muy bajo como 1e-10.
Ejemplo concreto: el efecto de la temperatura
Para ver esto en acción, ejecuté el mismo prompt con un modelo real (Qwen3-4B) usando diferentes temperaturas:
Prompt: “Escribe un haiku sobre programación”
Temperatura = 0.0000000001 (greedy, prácticamente determinístico):
Código en la noche, luz de la pantalla, pensamientos, lógica en cada línea.
Siempre genera exactamente esto. Elegante, coherente, predecible. Los tokens con mayor probabilidad en cada paso.
Temperatura = 0.7 (balanceado):
Código en la noche, pensamiento y error se dan la mano, luz en la oscuridad.
Variación interesante. Empieza similar (”Código en la noche”), pero toma un camino diferente. Nota cómo introduce la idea de “error” (muy apropiada para programación). Coherente y poético.
Temperatura = 1.5 (exploratorio):
Código en la mente, echo sin agucar, parches de esperanza.
Aquí empezamos a ver los efectos de temperatura alta. “echo sin agucar” es extraño (probablemente quiso decir “azúcar” pero el sampling eligió tokens menos probables). “Parches de esperanza” es poético pero muestra que el sistema está explorando tokens más raros, a costa de coherencia.
Temperatura = 2.0 (caótico):
Código en Crechter, TEST bàn, servicios asc únicos, errores autl/calzar.
Completamente incoherente. “Crechter” no es una palabra real. “TEST bàn” mezcla mayúsculas, minúsculas y caracteres acentuados sin sentido. “autl/calzar” es basura léxica.
¿Por qué pasa esto?
A temperatura=2.0, la distribución de probabilidades se volvió tan uniforme que tokens con probabilidades originalmente bajísimas (fragmentos raros del vocabulario, typos del dataset de entrenamiento) ahora tienen chance real de ser elegidos. El resultado es sintácticamente válido (son tokens reales del vocabulario) pero semánticamente caótico.
Observaciones clave de este experimento:
1. El patrón inicial persiste incluso con temperatura alta:
Todas las versiones empiezan con “Código en...”
Esto es porque en el primer token, después de solo el prompt, “Código” probablemente tiene una probabilidad muy alta (tal vez 60-70%). Incluso aplicando temperatura=2.0, sigue siendo más probable que alternativas raras.
Pero una vez que el contexto incluye tokens extraños (como “Crechter” en temperatura=2.0), los siguientes tokens se generan basándose en ese contexto corrupto, y el colapso en incoherencia es rápido.
2. Temperatura alta no es “creatividad gratis”:
Temperatura=1.5 dio “echo sin agucar” (probablemente un error de tokenización o typo del dataset). No es que el modelo se volvió creativo, es que el sistema está eligiendo tokens menos probables, algunos de los cuales son fragmentos raros, errores ortográficos, o artefactos del entrenamiento.
3. La temperatura óptima depende totalmente de tu tarea:
Para este haiku: 0.7 dio el mejor balance
Para código: 0.0-0.3 (quieres precisión, no creatividad)
Para respuestas factuales: 0.0-0.1 (determinismo)
Para brainstorming: 1.0-1.2 (exploración controlada)
Para arte generativo experimental: 1.5-2.0 (asumiendo que la incoherencia es aceptable)
Otras estrategias de sampling: top-k y top-p
La temperatura controla cómo de plana o pronunciada es la distribución de probabilidades, pero considera todos los tokens del vocabulario (incluso los que tienen probabilidad cercana a cero).
Las siguientes estrategias van un paso más allá: filtran qué tokens se consideran antes de samplear, ignorando completamente opciones muy improbables.
Top-k sampling: limitar a los k más probables
Esta estrategia es conceptualmente simple: después de calcular probabilidades, solo considera los k tokens con mayor probabilidad, descarta el resto, y samplea entre esos k.
Algoritmo:
Calcular probabilidades de todos los tokens (aplicando temperatura si corresponde)
Ordenar tokens por probabilidad de mayor a menor
Seleccionar los primeros k tokens
Descartar todos los demás (probabilidad = 0)
Re-normalizar las probabilidades de los k seleccionados para que sumen 1
Samplear aleatoriamente entre esos k tokens
Ejemplo con k=3:
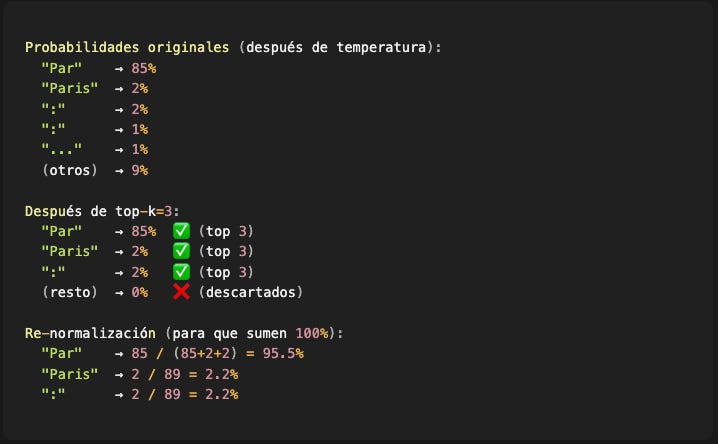
Ventajas de top-k:
Previene basura: Tokens muy improbables (typos, fragmentos raros) nunca serán elegidos, incluso con temperatura alta
Simple de implementar: Un sort y un slice
Predecible: k=1 es equivalente a greedy, k=vocabulario_completo es sampling sin restricción
Desventajas:
Rígido: Siempre considera exactamente k tokens, sin importar si el modelo está muy confiado (un token con 99%) o muy indeciso (10 tokens con ~10% cada uno)
Puede descartar opciones válidas: Si el modelo está indeciso y hay 5 tokens buenos con ~15% cada uno, pero k=3, perderás 2 opciones razonables
Valores típicos de k:
k=1: Greedy (determinístico)
k=10-20: Conservador, solo opciones muy probables
k=40-50: Balanceado, usado frecuentemente
k=100+: Permisivo, similar a no usar restricción
Top-p sampling (nucleus sampling): límite adaptable
Top-p resuelve el problema de rigidez de top-k siendo adaptable según la confianza del modelo.
En lugar de un número fijo de tokens, top-p incluye tokens hasta que la probabilidad acumulada llegue a p (típicamente 0.9 o 0.95).
Algoritmo:
Calcular probabilidades de todos los tokens (aplicando temperatura si corresponde)
Ordenar tokens por probabilidad de mayor a menor
Ir sumando probabilidades acumuladamente
Incluir tokens mientras la suma acumulada sea ≤ p
Descartar todos los tokens fuera de ese “núcleo”
Re-normalizar las probabilidades del núcleo para que sumen 1
Samplear aleatoriamente dentro del núcleo
Ejemplo con p=0.9:
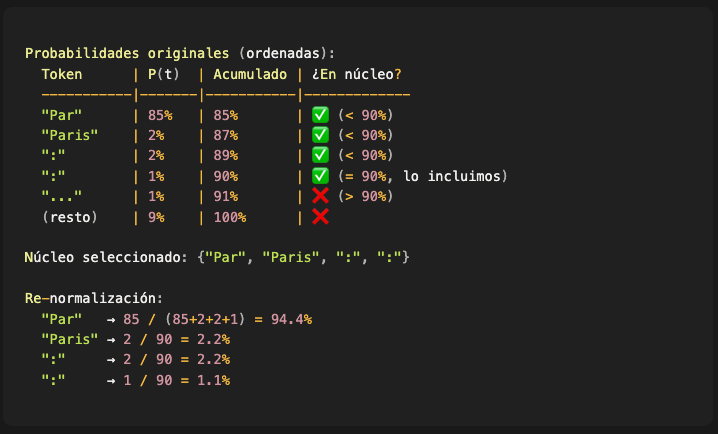
Ventajas de top-p:
Adaptable: Cuando el modelo está muy confiado (un token con 95%), el núcleo es pequeño (1-2 tokens). Cuando está indeciso (varios tokens con ~10%), el núcleo crece automáticamente
Previene basura: Similar a top-k, descarta la “cola larga” de tokens improbables
Más natural: Se ajusta a la incertidumbre real del modelo en cada paso
Desventajas:
Ligeramente más complejo de implementar: Requiere ordenar y buscar el punto de corte
Menos intuitivo: k=50 es fácil de entender, p=0.9 requiere explicar la probabilidad acumulada
Valores típicos de p:
p=0.0: Equivalente a greedy
p=0.5-0.7: Muy conservador, solo el núcleo más confiado
p=0.9: Balanceado, recomendado para uso general
p=0.95: Permisivo, permite más variación
p=1.0: Sin restricción (considera todo el vocabulario)
Comparación: temperatura vs top-k vs top-p

La mayoría de sistemas modernos usan temperatura + top-p con una configuración típica de:

Y algunos sistemas permiten combinar los tres:

El orden de aplicación es:
Aplicar temperatura a los logits
Calcular softmax → probabilidades
Aplicar top-k (si está configurado)
Aplicar top-p (si está configurado)
Re-normalizar
Samplear
En un próximo artículo, implementaré un sistema de inferencia y verás cómo implementar estas estrategias en código.
El loop autoregresivo: generación token por token
Aquí está el concepto que cambia completamente cómo entiendes la generación de texto:
La respuesta NO se genera de una vez. Se construye token por token en un loop.
Pero hay una distinción fundamental que necesitas entender.
Separando responsabilidades: modelo vs sistema de inferencia
El modelo transformer (LLM) hace UNA cosa: dado un conjunto de tokens de entrada, produce logits (scores) para cada token del vocabulario.
En realidad, los transformers no son modelos “predictivos” en el sentido tradicional. Son clasificadores. Le das una secuencia de tokens y te devuelve una distribución de probabilidad (en forma de logits) sobre todas las posibles “clases” (tokens del vocabulario) que podrían venir después.
El modelo no decide cuál token elegir. No hace sampling. No aplica softmax. Solo clasifica: “estos son los scores que le asigno a cada posible siguiente token, basándome en lo que vi hasta ahora”.
Todo lo demás (softmax, sampling, el loop mismo) es responsabilidad del sistema de inferencia (el código que nosotros escribimos).
Esta separación es clave porque significa que:
El mismo modelo puede comportarse completamente diferente según cómo lo uses
Puedes modificar todo el comportamiento de generación sin tocar el modelo
El control real está en el sistema de inferencia, no en los pesos del modelo
El loop completo (con responsabilidades claras):
Veamos el proceso real, distinguiendo qué hace el modelo y qué hace nuestro código:
Iteración 1:
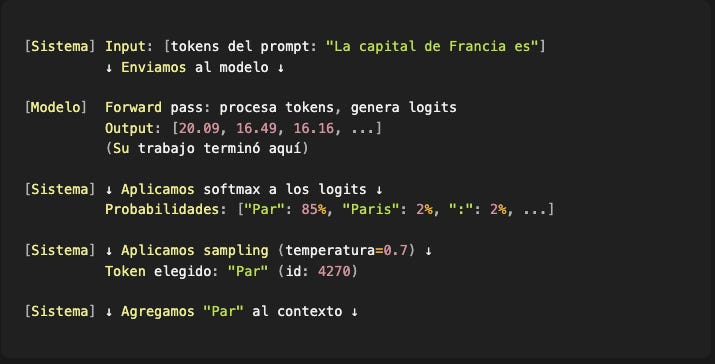
Iteración 2:
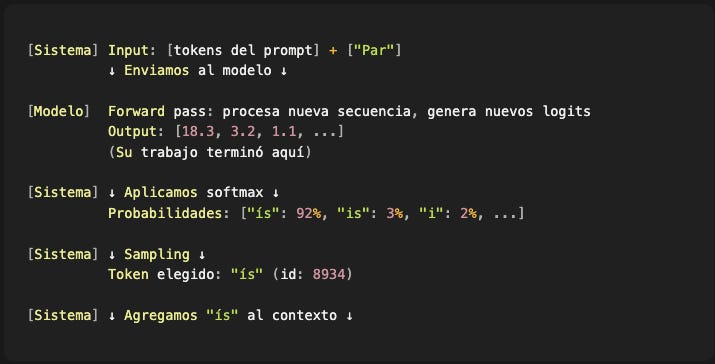
Iteración 3:
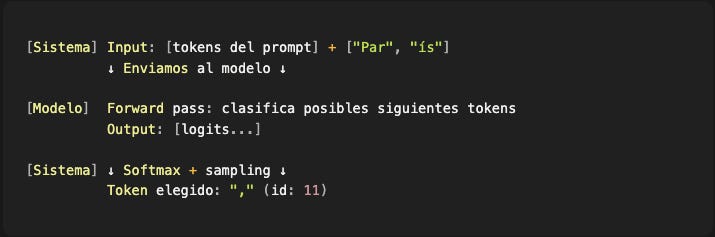
...y el sistema repite hasta:
Detectar un token especial de fin (
<|im_end|>,</s>, etc.)Alcanzar el límite máximo de tokens configurado
Cumplir alguna condición de parada que definamos
Por qué esta distinción importa
1. El modelo es determinístico (dado el mismo input)
Si le pasas exactamente los mismos tokens al modelo 1000 veces, obtienes exactamente los mismos logits 1000 veces. El modelo no tiene “memoria” entre llamadas, no toma decisiones probabilísticas.
2. La variabilidad viene del sistema de inferencia
Cuando ves respuestas diferentes para el mismo prompt, eso viene del sampling (random), no del modelo. El modelo siempre propone la misma distribución; nosotros elegimos aleatoriamente de esa distribución.
3. Todo el control está en nuestras manos
¿Quieres forzar JSON válido? Modifica los logits antes del softmax
¿Quieres banear ciertos tokens? Pon sus logits en −∞−∞
¿Quieres cambiar completamente el comportamiento? Cambia la estrategia de sampling
El modelo sigue siendo el mismo, solo cambias cómo interpretas y usas sus outputs.
Por qué se llama “autoregresivo”
Porque el sistema alimenta la salida del paso anterior como entrada del siguiente paso. No es que el modelo sea autoregresivo por sí mismo; es que lo usamos de forma autoregresiva.
El modelo simplemente clasifica cada vez que se lo pedimos. Nosotros orquestamos el loop.
Implicaciones prácticas de esta arquitectura:
1. Por qué tarda en generar respuestas largas
Cada token requiere:
[Modelo] Un forward pass completo (la parte cara computacionalmente)
[Sistema] Softmax (barato)
[Sistema] Sampling (muy barato)
[Sistema] Actualización del contexto (barato)
Una respuesta de 200 tokens significa 200 forward passes del modelo. Eso es lo que consume tiempo y recursos, no el código alrededor.
2. Por qué el contexto puede “perderse”
El modelo no tiene memoria persistente. En cada llamada, solo ve:
Los tokens que le enviamos
Sus propios pesos (fijos)
Si en el token 50 nuestro sistema eligió un token que se desvía del prompt original, el modelo no puede “recordar” la intención original en el token 100. Solo ve el contexto actual (que incluye esa desviación).
No es que el modelo “se olvidó”. Es que nunca tuvo memoria para empezar; solo clasifica basándose en la entrada actual.
3. Por qué los modelos pueden “cambiar de opinión”
El modelo no cambió de opinión. En cada llamada, simplemente clasificó basándose en el contexto que le dimos.
Si el contexto empezó con “Python es excelente...” y luego nosotros (el sistema) elegimos tokens que llevaron a “...pero cuando se trata de performance...”, el modelo en la siguiente llamada clasifica coherentemente con ese nuevo contexto.
El modelo no planeó ir de Python a Rust. Nosotros construimos ese camino token por token, y el modelo solo clasificó en cada paso.

Cuando hablamos de “hacer que el modelo haga X”, en realidad estamos hablando de cómo usamos el modelo, no de cambiar el modelo mismo.
Esta distinción es fundamental para entender dónde tienes control real sobre el comportamiento de la generación.
Por qué todo esto importa en la práctica
Ahora que entiendes estos tres conceptos (tokens, logits, sampling), la separación entre modelo y sistema de inferencia, y el loop autoregresivo, varios comportamientos “misteriosos” de los LLMs empiezan a tener sentido:
1. Formatos inconsistentes
Problema: Le pides JSON al modelo y a veces funciona, a veces no.
Razón: El modelo está clasificando tokens independientemente en cada paso, sin “saber” que estás construyendo JSON. El sistema de inferencia samplea cada token según probabilidades, y no hay garantía de que la secuencia completa forme una estructura válida.
El modelo puede generar logits altos para {, luego para "nombre", luego para :, pero en algún paso los logits podrían favorecer un token que rompe la sintaxis JSON. Como el sistema samplea probabilísticamente, ese token problemático puede ser elegido.
Solución (que veremos en artículos futuros): Modificar los logits antes del sampling para forzar que solo tokens válidos según la gramática JSON tengan probabilidad > 0. Esto lo hace el sistema de inferencia, no el modelo. Se llama “guided generation” o “constrained decoding”.
2. Alucinaciones
Problema: El modelo genera información falsa con total confianza.
Razón: El modelo es un clasificador entrenado con patrones estadísticos de texto. No “sabe” hechos, solo aprendió qué tokens suelen seguir a otros.
Si durante el entrenamiento vio muchas veces “El CEO de Apple es Steve Jobs” y pocas veces información actualizada, sus logits reflejarán ese patrón histórico. El modelo clasifica basándose en correlaciones estadísticas, no en verdad factual.
Además, una vez que el sistema de inferencia elige un token incorrecto, ese token pasa a formar parte del contexto. En las siguientes iteraciones, el modelo clasifica coherentemente con ese contexto corrupto, propagando el error.
Solución: Retrieval-Augmented Generation (RAG). Antes de llamar al modelo, el sistema añade información verificada al contexto. El modelo sigue clasificando basándose en patrones, pero ahora esos patrones están anclados en datos correctos. Lo cubriremos en profundidad en artículos futuros.
3. Repetición de frases
Problema: El modelo repite la misma frase o patrón indefinidamente.
Razón: Si el sistema de inferencia construyó un contexto que forma un patrón repetitivo (listas, estructuras), el modelo clasificará consistentemente que ese patrón debe continuar:
Cada clasificación individual del modelo es correcta (está prediciendo coherentemente con el patrón). El problema es el ciclo que el sistema permite.
Solución: Penalización de repetición (repetition penalty). El sistema de inferencia modifica los logits de tokens que aparecieron recientemente, reduciendo su probabilidad antes del sampling. No cambias el modelo, cambias cómo usas sus outputs.
4. Sensibilidad al prompt
Problema: Cambios mínimos en el prompt (añadir un punto, cambiar una palabra) producen resultados completamente diferentes.
Razón: Cada cambio en el texto modifica los tokens de entrada, lo que hace que el modelo (que es determinístico) produzca una distribución de logits diferente.
El modelo responde a lo que le das. Un token extra no es un “detalle menor” para el modelo; es literalmente diferente input, por lo tanto diferente clasificación.
Luego, el sistema samplea de esas distribuciones diferentes, y pequeñas diferencias iniciales pueden llevar a caminos completamente distintos en el loop autoregresivo.
5. Latencia y costo
Problema: Las respuestas tardan mucho y las APIs cobran caro por respuestas largas.
Razón: El cuello de botella es el modelo. Cada forward pass requiere:
Multiplicaciones de matrices masivas (millones/miles de millones de parámetros)
Cálculos de atención sobre todo el contexto
Hardware especializado (GPUs/TPUs)
El sistema de inferencia (softmax, sampling) es computacionalmente barato. Lo caro son las N llamadas al modelo para generar N tokens.
Por qué las APIs cobran por token: Cada token significa un forward pass completo del modelo. Generar 1,000 tokens es literalmente 1,000 veces más caro en cómputo que generar 1 token.
Soluciones:
Límites de longitud: El sistema corta la generación después de N tokens
Top-k/top-p: Evitan que el sistema explore caminos divergentes que generan mucho texto
Modelos locales: El costo es fijo (tu hardware), no por token
Prompts concisos: Menos tokens de entrada = forward passes más rápidos
La diferencia entre usar y dominar
Si solo usas LLMs con parámetros por defecto a través de APIs, todo esto es información interesante pero no esencial. Las APIs abstraen estos detalles por una buena razón: la mayoría de los casos de uso no necesitan este nivel de control.
Pero si quieres:
✅ Controlar exactamente qué puede generar el sistema
Banear tokens específicos (modificando logits)
Forzar formatos (constrained decoding)
Garantizar consistencia (determinismo o sampling controlado)
✅ Debuggear comportamientos extraños
¿Por qué repite? → Analiza el contexto y los logits
¿Por qué ignora el prompt? → Revisa cómo tokeniza
¿Por qué alucina aquí? → Inspecciona qué patrones aprendió
✅ Optimizar latencia y costo
Entender que cada token = 1 forward pass
Saber dónde cortar sin perder calidad
Decidir si usar un modelo más pequeño es viable
✅ Construir sistemas predecibles en producción
“Funciona el 95% del tiempo” no es suficiente
Necesitas garantías, no probabilidades
El control está en el sistema de inferencia
✅ Adaptar el comportamiento sin reentrenar
Custom sampling strategies
Logit processors dinámicos
Combinaciones de modelos
...entonces necesitas entender este proceso a fondo.
Porque la diferencia entre “usar un LLM” y “construir sistemas con LLMs” está en cuánto control tienes sobre cada componente:
Tokenización (cómo el texto se convierte en números)
Forward pass del modelo (qué logits produce)
Modificación de logits (cómo influyes en las probabilidades)
Sampling (cómo eliges tokens)
Orquestación del loop (cómo construyes la respuesta completa)
Las APIs te dan el resultado final. Entender el proceso te da las herramientas para controlar ese resultado.
Qué sigue
Ahora tienes la intuición fundamental de cómo funcionan estos sistemas. Entiendes:
Tokens: Cómo el texto se convierte en números (y por qué tokenizer y modelo están ligados)
Logits: Cómo el modelo clasifica posibles siguientes tokens (scores crudos, no probabilidades)
Sampling: Cómo el sistema de inferencia elige tokens (temperatura, top-k, top-p)
Loop autoregresivo: Por qué es un proceso iterativo (modelo clasifica → sistema elige → repite)
Separación de responsabilidades: Modelo vs sistema de inferencia (dónde está el control real)
En el próximo artículo, vamos a implementar este proceso desde cero. Vamos a:
Cargar un modelo local (Qwen3-4B quantized) usando Rust y Candle
Escribir el código del sistema de inferencia que orquesta el loop
Ver los logits reales que produce el modelo en cada paso
Implementar diferentes estrategias de sampling (greedy, temperatura, top-k, top-p)
Construir un generador completo que puedas modificar y adaptar
Sin APIs externas. Sin frameworks que oculten lo que está pasando. Solo código que entiendes línea por línea.
Verás exactamente dónde termina el trabajo del modelo y dónde empieza el tuyo. Y tendrás control total sobre cada decisión en el proceso de generación.
Porque entender cómo funciona algo es el primer paso. Construirlo tú mismo es cuando realmente lo dominas.
Si este artículo te resultó útil, compártelo con alguien que esté aprendiendo sobre LLMs.
¿Tienes preguntas o comentarios? Puedes dejarlos en el post. Todas las discusiones técnicas son bienvenidas.