What Happens When an LLM 'Thinks': Tokens, Logits, and Sampling
A deep dive into the three fundamental concepts that explain LLM behavior: tokens, logits, and sampling strategies.
You send a prompt. The model “thinks” for a few seconds. And generates a response that seems intelligent.
What happened in that time?
If your way of implementing systems with LLMs is based on using a high-level framework plus OpenAI APIs and derivatives, you probably don’t understand how this “thinking” process works. And that’s fine — APIs are designed precisely so you don’t have to know. But if you want to build serious systems around LLMs, you need to understand what’s happening under the hood.
Because when your application needs the model to always generate valid JSON, or when you want to guarantee it never mentions sensitive information, or when you simply want to understand why it sometimes “hallucinates” information… that’s when “calling an API and hoping for the best” stops being enough.
The good news is this isn’t magic. It’s a fairly elegant process of applied mathematics and probability. And once you understand the three fundamental concepts — tokens, logits, and sampling — all the strange behavior of LLMs starts to make sense.
The Black Boxes
If you work with LLMs today, part of your code probably looks like this:
import openai
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Explain quantum computing"}]
)
print(response.choices[0].message.content)It works. It solves problems. But it’s completely opaque.
You don’t know why the model:
- Generates inconsistent formats (sometimes valid JSON, sometimes not)
- Occasionally “hallucinates” false information with absolute confidence
- Refuses to answer certain questions but not other similar ones
- Produces different results each time (even with the same prompt)
When something fails, your only tool is adjusting the prompt and hoping it works better. It’s debugging by trial and error.
The problem is these APIs are designed precisely to hide the generation process. You only see the input and the final output. Along with what you send to the API, there’s a set of tags and rules attached to your prompt to control the model’s behavior according to the provider’s interests and security measures — which aren’t necessarily aligned with your project’s objectives.
To have real control, you need to understand what happens in between. And it all starts with three fundamental concepts.
Concept 1: Tokens — the real language of models
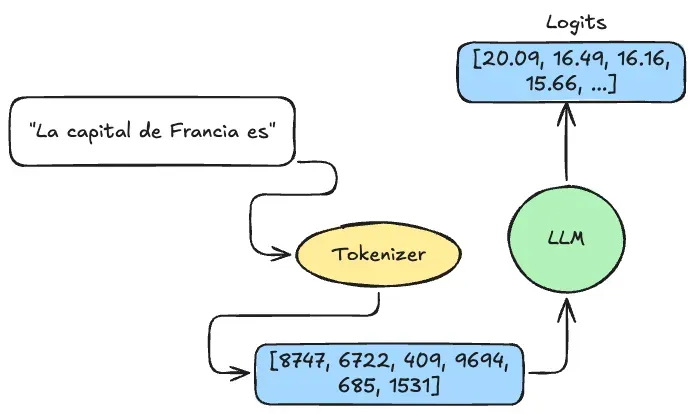
Language models don’t read text like we do. They read numbers (more specifically, vectors).
When you send a prompt, the first thing that happens is the text is converted into a sequence of numbers called tokens. This process is done by a component called a tokenizer.
Prompt: "Hello, world!"
Tokens: [9707, 11, 1879, 0]Each number represents a “piece” of text from the model’s vocabulary. Typical vocabularies have between 100,000 and 200,000 different tokens, depending on the model (Qwen3, for example, has over 150,000 tokens).
Important: The tokenizer and model are intimately linked. A model can only process tokens generated by the same tokenizer used during its training. You can’t arbitrarily interchange them.
What exactly is a token?
It’s not always a complete word:
- The word “Engineer” could be 1 token or 3, depending on the tokenizer
- “I’m” is typically 2 tokens: “I” and “‘m”
- ”🤖” (emoji) could be 1 or more tokens
- Spaces and punctuation marks are also tokens
Why this matters:
- Context window limits are measured in tokens, not words. “Maximum context window of 4,096” means 4,096 tokens. In English, approximately 1 token ≈ 0.75 words. In Spanish or with code, the ratio changes significantly.
- Tokens determine what the model can “understand”. If a rare word was divided into 5 tokens, the model has to reconstruct its meaning from those pieces.
- API costs are calculated per token. More tokens = more money. Concise prompts cost less.
The model never sees your original text. It only sees a sequence of numbers. All its “understanding” is based on patterns it learned about how those numbers relate to each other.
Concept 2: Logits — the model’s “opinions” about what comes next
Once the model processes the prompt’s tokens, it generates something called logits.
Logits are a vector of numbers (scores) representing “how likely each token in the vocabulary is to be next”. If the vocabulary has 151,669 tokens (as in Qwen3), you get 151,669 scores.
Real example:
Imagine the prompt is: “La capital de Francia es”
top_5_logits:
- token: "Par"
value: 20.09
- token: "Paris"
value: 16.49
- token: ":"
value: 16.16
- token: "."
value: 15.67
- token: "..."
value: 15.67The numbers aren’t probabilities yet — they’re raw scores:
- High scores (20.09) = very likely tokens
- Low or negative scores = unlikely tokens
From logits to probabilities
Logits are transformed into probabilities using a mathematical function called softmax. Conceptually, softmax takes those scores and converts them into values between 0 and 1 that sum to 1.
| Token | Logit | Probability |
|---|---|---|
| ”Par” | 20.09 | 85% |
| “Paris” | 16.49 | 2% |
| ”:“ | 16.16 | 2% |
| ”.“ | 15.67 | 1% |
| ”…“ | 15.67 | 1% |
| (others) | … | 9% |
Why “Par” has 85% while “Paris” only 2%?
Because our prompt is in Spanish. The model detects the context’s language and adjusts its predictions accordingly. Since the tokenizer may not have a single token for “París” (with accent), the model opts for a fragmentation strategy: it generates “Par” first, knowing it will generate “ís” in the next iteration to complete the accented word.
This is a perfect example of how the model doesn’t just “predict tokens” — it adapts its predictions according to linguistic context.
Note: Logits are calculated only for the last position of the sequence. The model isn’t predicting the entire response at once — only the next token. This is the heart of the autoregressive process.
Concept 3: Sampling — how to choose the next token
We have probabilities for each vocabulary token. Now comes the key question: how do we choose which one to use?
Here’s an important detail: the model doesn’t choose the next token. The model’s job ends when it generates the logits. Everything that comes after — converting logits to probabilities with softmax, and choosing the next token — is the inference system’s responsibility.
This is a critical distinction: you can take the same model and completely change its behavior just by modifying the sampling strategy, without touching the model at all.
Strategy 1: Greedy sampling (temperature = 0)
Always choose the token with the highest probability.
Characteristics:
- Deterministic: Run the same prompt 100 times and get exactly the same response
- Safe: Chooses the “most correct” option according to the model
- Ideal for: Code generation, factual responses, strict formats (JSON, tables)
Strategy 2: Random sampling (temperature > 0)
Instead of always choosing the most likely, the model samples randomly according to probabilities. This introduces variability.
The temperature parameter:
Temperature modifies the logits before applying softmax:
adjusted_logits = logits / temperature
probabilities = softmax(adjusted_logits)| Temperature | Behavior | When to use |
|---|---|---|
| 0.0 | Greedy: always picks the most probable | Code, data, precise tasks |
| 0.1 - 0.3 | Almost deterministic, minimal variation | Technical responses |
| 0.5 - 0.8 | Balance between coherence and creativity | Conversations, writing |
| 1.0 - 1.5 | Very creative, can deviate from topic | Brainstorming, fiction |
| 2.0+ | Chaotic, frequently incoherent | Experimentation |
Top-k sampling: limit to the k most likely
After calculating probabilities, only consider the k tokens with highest probability and discard the rest.
- Advantage: Prevents garbage — very unlikely tokens will never appear
- Disadvantage: Rigid — always considers exactly k tokens regardless of model confidence
- Typical values: k=1 (greedy), k=40-50 (balanced), k=100+ (permissive)
Top-p sampling (nucleus sampling): adaptive limit
Instead of a fixed number of tokens, top-p includes tokens until cumulative probability reaches p (typically 0.9 or 0.95).
- Advantage: Adaptive — when the model is very confident (one token with 95%), the nucleus is small. When undecided, it grows automatically.
- Typical values: p=0.9 (balanced), p=0.95 (permissive)
The application order is:
- Apply temperature to logits
- Calculate softmax → probabilities
- Apply top-k (if configured)
- Apply top-p (if configured)
- Re-normalize
- Sample
The autoregressive loop: token-by-token generation
The response is not generated all at once. It’s built token by token in a loop.
The transformer model does one thing: given a set of input tokens, it produces logits for each vocabulary token. It’s more of a classifier than a “generative” model in the traditional sense. Everything else — softmax, sampling, the loop — is the inference system’s responsibility.
# Iteration 1
input_tokens = tokenizer.encode("The capital of France is")
logits = model(input_tokens)
probs = softmax(logits / temperature)
filtered_probs = apply_top_p(probs, p=0.9)
next_token = sample(filtered_probs) # e.g., "Par"
input_tokens.append(next_token)
# Iteration 2
logits = model(input_tokens) # now includes "Par"
# ... repeat until end token or max lengthWhy this distinction matters:
- Variability comes from sampling, not the model. The model is deterministic (same input → same logits). Different responses come from random sampling.
- All control is in the inference system. Want to force valid JSON? Modify logits before softmax. Want to ban tokens? Set their logits to -∞. The model stays untouched.
- Why generation takes time. Each token requires a complete forward pass of the model — 200 tokens means 200 forward passes. That’s what consumes time and resources.
Why it’s called “autoregressive”
Because the system feeds the previous step’s output as input to the next step. The model simply classifies each time we ask. We orchestrate the loop.
Why this matters in practice
Once you understand tokens, logits, and sampling, several “mysterious” LLM behaviors start making sense:
- Inconsistent formats: The model classifies tokens independently. There’s no guarantee the complete sequence forms valid JSON — unless the inference system forces it (constrained decoding).
- Hallucinations: The model doesn’t “know” facts — it learned what tokens usually follow others. If it saw “Apple’s CEO is Steve Jobs” more often than updated information, it repeats that pattern.
- Phrase repetition: If the context forms a repetitive pattern, the model will consistently predict the pattern should continue. Fix: repetition penalty (modify logits of recently used tokens).
- Prompt sensitivity: Each text change modifies input tokens, which changes logit distributions. Those different distributions lead to different sampling paths.
- Latency and cost: The bottleneck is the model forward pass. The inference system (softmax, sampling) is cheap. APIs charge per token because each token = one forward pass.
The difference between using and mastering
If you only use LLMs through APIs, all this is interesting but not essential. APIs abstract these details for good reason.
But if you want to:
- Control exactly what the system generates — ban tokens, force formats, guarantee consistency
- Debug strange behaviors — analyze context and logits instead of blindly tweaking prompts
- Optimize latency and cost — understand where to cut without losing quality
- Build predictable production systems — “works 95% of the time” isn’t enough
- Adapt behavior without retraining — custom sampling strategies, dynamic logit processors
…then you need to understand this process deeply.
The difference between “using an LLM” and “building systems with LLMs” is in how much control you have over each component: tokenization, the model forward pass, logit modification, sampling, and loop orchestration.
APIs give you the final result. Understanding the process gives you the tools to control that result.