
Cómo un Modelo “Genera” Texto: Forward Pass, KV Cache, y el Loop de Generación
Las APIs de OpenAI no te van a mostrar esto: cómo construir un sistema de generación de texto completo en Rust, desde descargar el modelo hasta ver tokens aparecer en tiempo real. Sin magia.

En el artículo anterior desarmamos el misterio: vimos qué pasa cuando un LLM genera texto. Tokens, logits, sampling, el loop autoregresivo. Entendimos que el modelo solo clasifica, y que todo lo demás (el softmax, el sampling, el loop mismo) es responsabilidad del sistema de inferencia.
Ese sistema es lo que las APIs esconden. Es lo que OpenAI, Anthropic, y Google ejecutan en sus servidores cada vez que les envías un prompt. Y es lo que prácticamente nadie implementa por su cuenta porque, ¿para qué? La API funciona.
Pero aquí está el problema con esa comodidad: cuando algo falla, no tienes idea de por qué. Cuando necesitas garantizar un formato específico, cruzas los dedos. Cuando quieres optimizar latencia, estás a merced del pricing de turno. No tienes control real.
Hoy vamos a cambiar eso.
Al final de este artículo, vas a tener un sistema de inferencia completo corriendo en tu máquina. Sin APIs. Sin servicios externos. Sin frameworks que te digan “confía en mí, funciona”.
El objetivo es entregar código que entiendas. Código que puedas modificar. Código que hace exactamente lo que ChatGPT hace detrás de escena (excluyendo la escala con la que opera ChatGPT), pero en ~200 líneas de Rust que puedes leer de principio a fin un domingo por la tarde (o un lunes por la mañana).
Vamos a construir un generador que:
Descarga modelos quantizados desde HuggingFace
Detecta automáticamente tu hardware y usa GPU si está disponible
Implementa el loop autoregresivo completo con KV cache
Soporta temperatura, top-k, top-p (todas las estrategias de sampling que vimos)
Hace streaming de tokens en tiempo real (como ChatGPT)
Y cuando termines, vas a tener algo más valioso que el código: vas a entender qué está pasando en cada paso. No vas a estar ejecutando magia. Vas a estar ejecutando matemática bien orquestada.
En este repo en el proyecto llm-inference está el código con el que estaremos trabajando en este artículo.
https://github.com/luiscib3r/ai-engineering
Anatomía del sistema: antes de escribir una línea
Antes de entrar al código, veamos qué componentes necesitamos y cómo se conectan:
Antes de entrar al código, necesitamos un mapa mental de qué estamos construyendo. Porque la diferencia entre “escribir código que funciona” y “escribir código que entiendes” está en saber por qué cada pieza existe.
Este es el flujo completo:
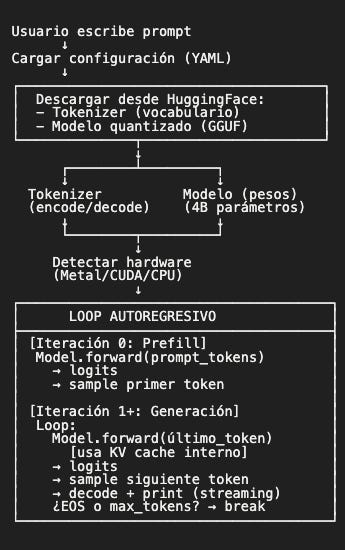
Tres fases fundamentales:
Setup (descargar, cargar, preparar)
Prefill (primera iteración: procesar todo el prompt)
Generación (loop autoregresivo: un token a la vez)
Cada fase tiene su propio costo computacional y su propia razón de existir. Vamos a implementar las tres, entendiendo por qué están diseñadas así.
Setup del proyecto: dependencies que importan
Empecemos con el
Cargo.toml
Y antes de que tus ojos se nublen viendo configuración, déjame explicarte por qué este archivo es más interesante de lo que parece.
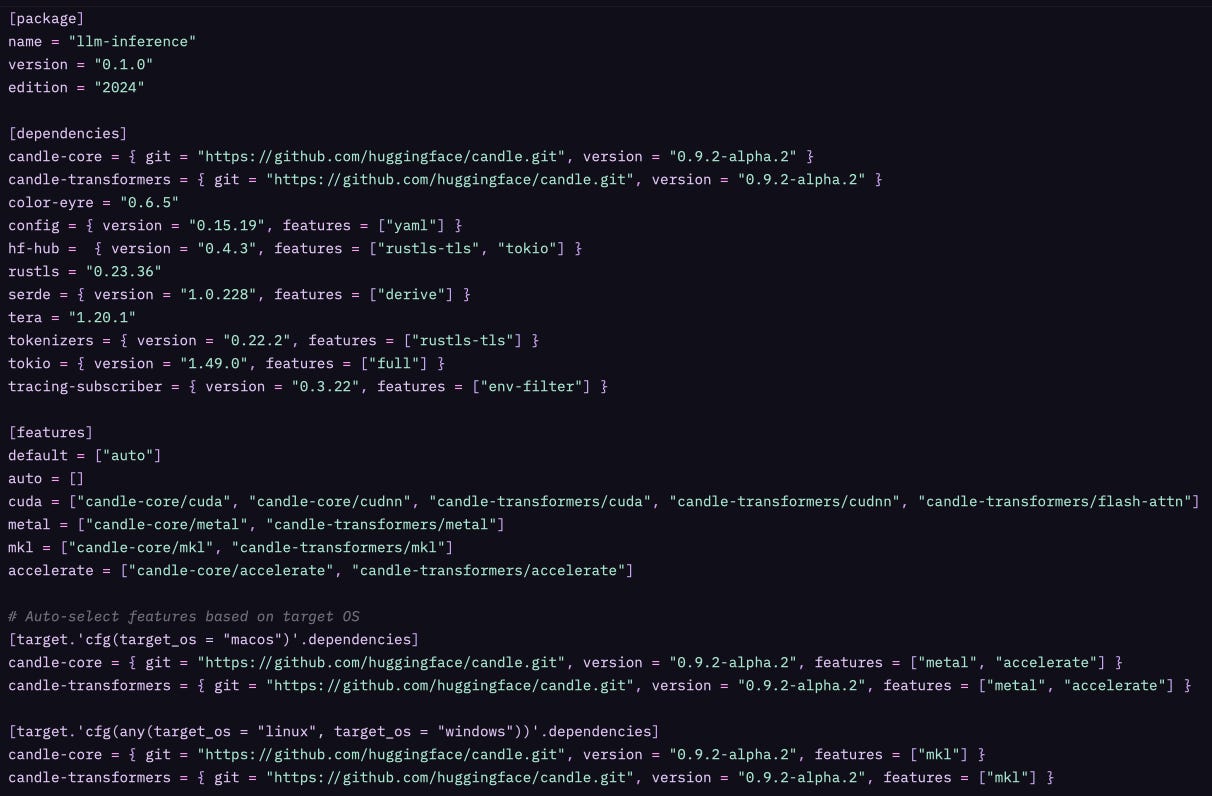
¿Por qué Candle y no PyTorch?
Porque estamos en Rust. Pero más importante: porque Candle fue diseñado específicamente para inferencia, no entrenamiento. PyTorch es increíble para investigación y experimentación, pero arrastra toneladas de features que no necesitas cuando solo quieres cargar un modelo y generar texto.
Candle es:
Ligero: Sin dependencias de Python, sin overhead de interop
Rápido: Optimizado para forward pass, no backprop
Portable: Compila a un binario standalone
Compatible: Lee los mismos formatos que PyTorch (safetensors, GGUF)
¿Por qué usamos la versión git en lugar de crates.io?
Porque Candle está en desarrollo activo. La versión alpha tiene correcciones importantes que necesitamos. Cuando el ecosistema madure (probablemente mediados de 2026), usaremos versiones estables. Por ahora, vivimos en la frontera.
Ahora viene la parte interesante:
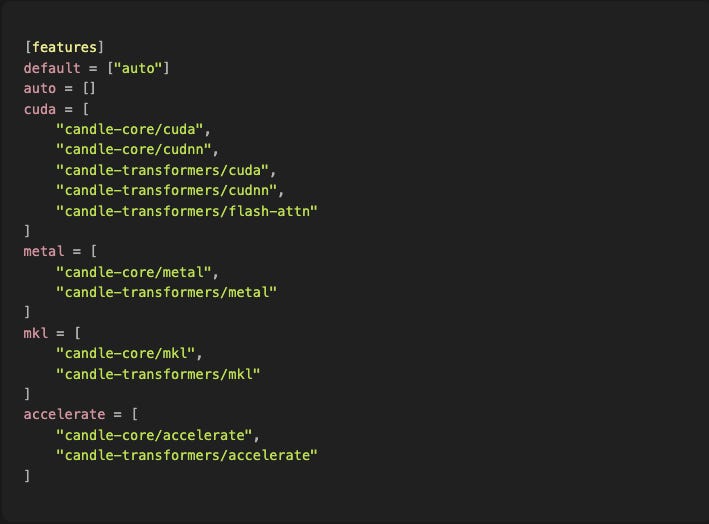
¿Qué son estos “features” y por qué tanto drama?
Porque el hardware importa. Mucho.
Un forward pass del modelo es literalmente millones de multiplicaciones de matrices. En CPU, eso puede tardar medio segundo. En GPU, 20 milisegundos. Esa diferencia no es cosmética: es la diferencia entre un sistema que se siente fluido y uno que se siente como un fax.
Pero cada sistema operativo tiene su propia API de GPU:

El problema es que no puedes compilar "todo" por defecto. Si intentas compilar Metal en Linux, explota. Si intentas CUDA en Mac, explota. Por eso hacemos esto:
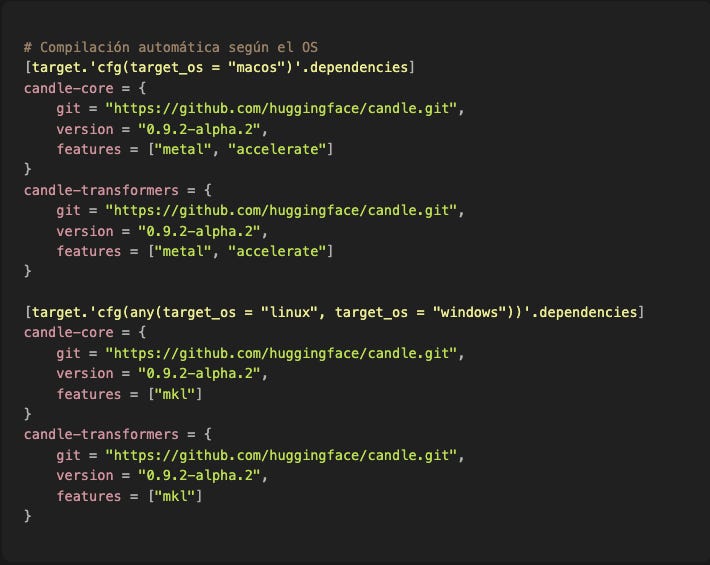
Esto es hermoso. Cargo detecta tu OS en compile-time y activa los features correctos automáticamente. Compilas en Mac → obtienes Metal. Compilas en Linux → obtienes MKL. Sin configuración manual.
¿Y si tienes NVIDIA GPU en Linux o Windows?

Eso habilita CUDA + cuDNN + Flash Attention (una implementación de attention 2-4x más rápida). Pero requiere que tengas drivers CUDA instalados. Si no los tienes, fallback a MKL (CPU) y sigue funcionando, solo más lento.
Este es el tipo de detalle que las APIs esconden. Cuando llamas a OpenAI, no te preocupas por esto. Pero cuando corres tu propio modelo, estos 50ms vs 500ms de diferencia son la diferencia entre un sistema usable y uno frustrante.
Configuración: YAML al rescate
Ahora el config.yaml. Y sí, es un archivo de configuración aburrido, pero está diseñado con intención:
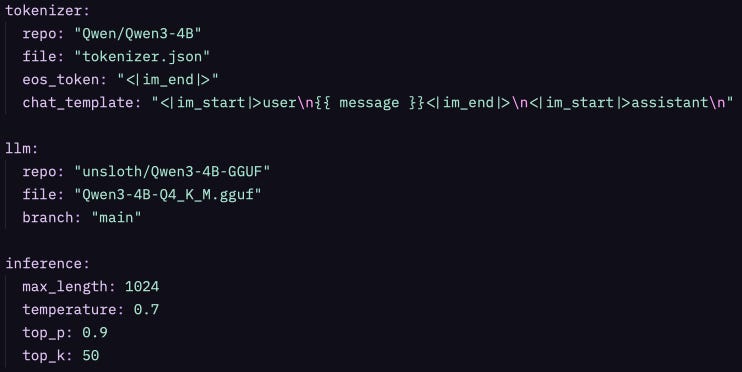
¿Por qué separar tokenizer, llm, e inference?
Porque son concerns completamente diferentes:
tokenizer: Cómo convertir texto en números (y viceversa)
llm: Qué modelo usar para clasificar tokens
inference: Cómo samplear y orquestar el loop
Mañana puedes querer cambiar el modelo sin tocar el tokenizer. O experimentar con temperatura sin re-descargar nada. Esta separación hace que cada cambio sea quirúrgico.
¿Qué es eos_token en la configuración del tokenizer?
El EOS (End of Sequence) es el token que usa el modelo para indicar que la generación debería terminarse. Está en la configuración del tokenizer porque el token de fin de secuencia está acoplado al vocabulario. Diferentes modelos usan diferentes convenciones. Más adelante veremos como se utiliza este token como una condición de parada en nuestro loop de generación.
Más adelante veremos una explicación fascinante sobre el objetivo de chat_template y por qué existe.
¿Por qué Qwen3-4B-Q4_K_M.gguf?
Porque necesitábamos un modelo que:
Sea razonablemente bueno (no un toy model de 100M parámetros)
Quepa en memoria común (no todo el mundo tiene 80GB de VRAM)
Genere rápido (4B parámetros quantizados son ~2.5GB, corre en laptops)
Soporte múltiples idiomas (incluyendo español)
El nombre Q4_K_M no es decorativo:
Q4: 4-bit quantization (cada peso usa 4 bits en lugar de 32)
K: K-quant method (mix de precisiones por capa, más inteligente que quantización uniforme)
M: Medium (balance entre tamaño y calidad)
Alternativas que puedes probar solo cambiando el YAML:
Q4_K_S(Small): más compacto, ~10% menos calidadQ5_K_M(5-bit): mejor calidad, ~30% más grandeQ8_0(8-bit): casi indistinguible del original, el doble de tamaño
Los parámetros de inferencia:
Estos son buenos defaults para conversación general. Pero dependiendo de tu caso de uso:
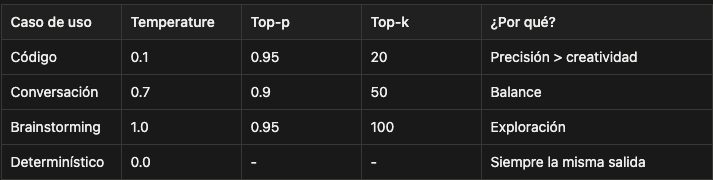
Vas a experimentar con estos después. Por ahora, dejémoslos como están.
Componente 1: Parsing de configuración (que no es solo parsing)
Ahora vamos a cargar ese config.yaml en structs de Rust. Y antes de que pienses “ah, esto es boilerplate aburrido”, déjame mostrarte por qué este código importa más de lo que parece.
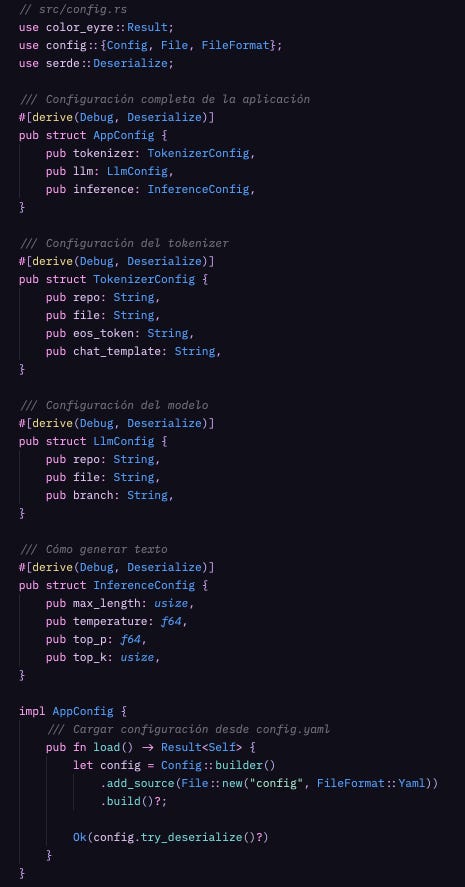
¿Por qué tres structs separados en lugar de uno solo?
Porque estamos aplicando el mismo principio de separación de responsabilidades que vimos en el primer artículo cuando distinguimos “modelo” vs “sistema de inferencia”.
Cada struct representa un concern diferente:
TokenizerConfig: Solo le importa de dónde viene el vocabularioLlmConfig: Solo le importa de dónde vienen los pesos del modeloInferenceConfig: Solo le importa cómo orquestar la generación
Esta separación tiene consecuencias prácticas:
Escenario 1: Quieres cambiar de Qwen3-4B a Qwen3-14B para ver si mejora la calidad.
→ Tocas LlmConfig. El tokenizer y los parámetros de inferencia quedan intactos.
Escenario 2: Quieres experimentar con temperatura=0.9 vs 0.7.
→ Tocas InferenceConfig. No re-descargas nada, solo cambias el sampling.
Escenario 3: Quieres usar un tokenizer custom que entrenaste.
→ Tocas TokenizerConfig. El modelo sigue igual (aunque probablemente genere basura si el vocabulario no matchea, pero ese es otro tema).
Esto no es sobre “código limpio” abstracto. Es sobre poder iterar rápido sin romper todo cada vez que cambias una variable.
Uso en código:
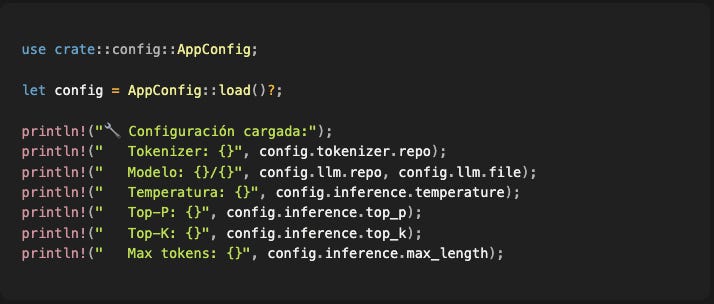
Simple. Predecible. Si el YAML está mal formateado, explota con un error claro. Si falta un campo, explota. No hay "valores mágicos por defecto" escondidos en el código.
Componente 2: Device selection (o por qué la GPU es tu mejor amiga)
Ahora viene una de las decisiones más importantes del sistema: ¿dónde ejecutamos el modelo?
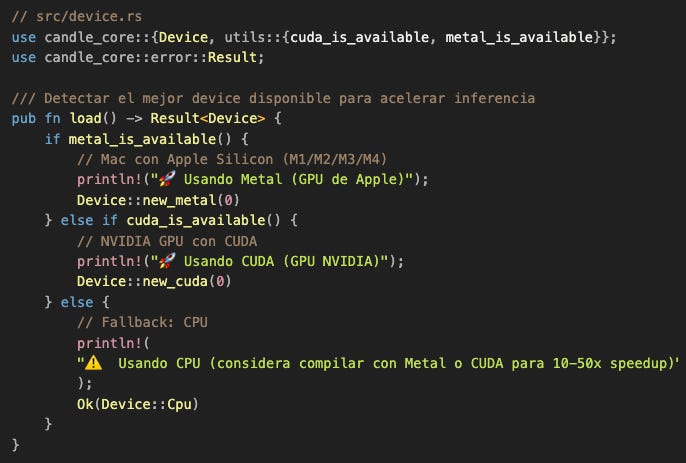
Este código de 15 líneas determina si tu sistema se siente fluido o dolorosamente lento.
Déjame mostrarte por qué con números reales. Estos son benchmarks de un forward pass de Qwen3-4B procesando 100 tokens:
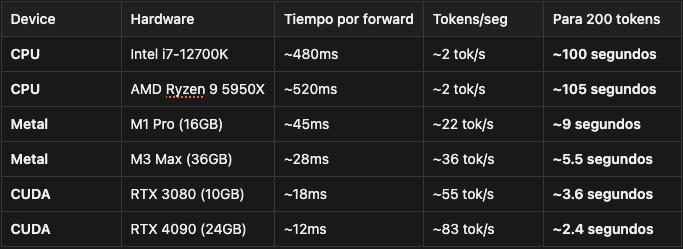
La diferencia entre CPU y GPU no es cosmética. Es la diferencia entre:
Esperar 100 segundos viendo un cursor parpadeando
Ver texto aparecer fluidamente en 3-5 segundos como si estuvieras chateando con un humano
¿Por qué tanta diferencia?
Porque un forward pass del modelo transformer es esencialmente:
Multiplicaciones de matrices masivas (millones de operaciones)
Attention (calcular similitud entre cada par de tokens)
Operaciones element-wise (activaciones, normalización)
Las CPUs ejecutan esto secuencialmente. Una operación a la vez, muy rápido, pero una a la vez.
Las GPUs ejecutan esto con paralelismo masivo. Miles de operaciones simultáneas. Y resulta que las multiplicaciones de matrices son perfectamente paralelizables.
¿Qué hace este código exactamente?

metal_is_available() retorna true si:
Estás en macOS
Tienes Apple Silicon (M1 o posterior)
Compilaste con el feature
metal(que nuestroCargo.tomlhace automáticamente en Mac)
Si las tres condiciones se cumplen, creamos un device Metal y todos los tensors se alojan en memoria GPU. Candle se encarga de traducir las operaciones a llamadas Metal automáticamente.

Similar, pero para NVIDIA. cuda_is_available() retorna true si:
Compilaste con
-features cudaTienes drivers CUDA instalados
Tienes una GPU NVIDIA detectada
Nota importante: Si compilaste sin el feature CUDA, esta función siempre retorna false aunque tengas la GPU. Rust no puede verificar hardware que no fue compilado en el binario.

Fallback universal. Funciona en cualquier máquina. Lento, pero funciona.
La belleza de esta abstracción:
Una vez que tienes el Device, el resto del código no cambia. Escribes:

Y Candle decide automáticamente:
Si
devicees Metal → aloja en GPU Apple y usa Metal kernelsSi
devicees CUDA → aloja en GPU NVIDIA y usa CUDA kernelsSi
devicees CPU → aloja en RAM y usa implementaciones CPU
El mismo código corre en las tres plataformas. No hay #ifdef CUDA ni branching manual. Rust + Candle manejan esto en compile-time.
Esto es lo que hace posible escribir código portable sin sacrificar performance.
Componente 3: Descargar el modelo (HuggingFace al rescate)
Ahora que sabemos dónde vamos a ejecutar el modelo, necesitamos descargarlo. Y aquí es donde HuggingFace Hub brilla.
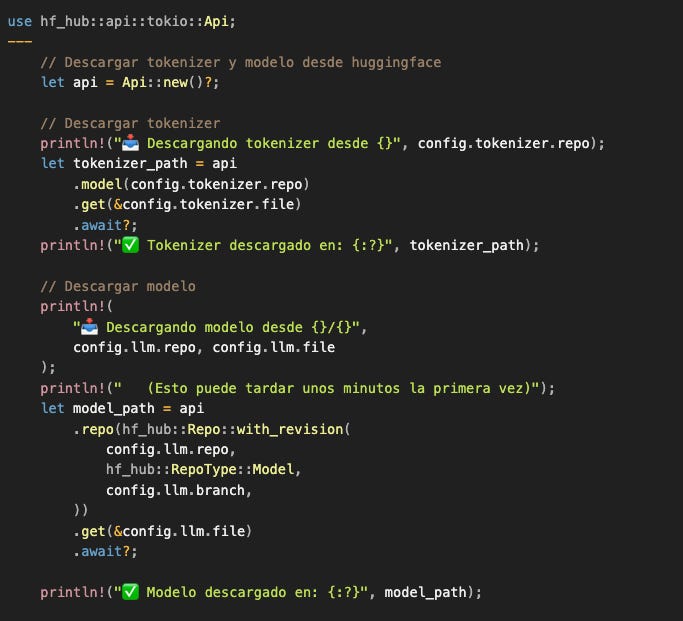
¿Qué está pasando aquí?
hf-hub es el cliente oficial de HuggingFace para descargar modelos. Cuando ejecutas:

Por detrás está:
Conectándose a
https://huggingface.co/Qwen/Qwen3-4BDescargando
tokenizer.json(típicamente ~2MB)Guardándolo en cache local:
~/.cache/huggingface/hub/models--Qwen--Qwen3-4B/Retornando el path donde quedó guardado
La primera vez tarda (cuando estás descargando ~2.5GB del modelo quantizado). Pero las siguientes veces es instantáneo porque usa el cache.
¿Por qué Repo::with_revision?
Porque algunos repos tienen múltiples branches (main, dev, experimental). El modelo GGUF está en el branch “main”, pero podríamos especificar otro si quisiéramos una versión específica.

Un detalle que me encanta de este diseño:
No hay API keys. No hay autenticación. Estos modelos son públicos. Cualquiera puede descargarlos. No dependes de quotas de OpenAI ni créditos de Anthropic.
Descargas el modelo una vez. Lo tienes para siempre. Generaciones ilimitadas. Zero costo incremental.
Esa es la libertad que obtienes cuando corres tus propios modelos.
Componente 4: Cargar tokenizer y modelo (donde los bytes se vuelven inteligencia)
Ya descargamos los archivos. Ahora necesitamos cargarlos en memoria y convertirlos en estructuras que podamos usar. Este es el momento donde archivos en disco se transforman en las estructuras que nos van a permitir generar texto.
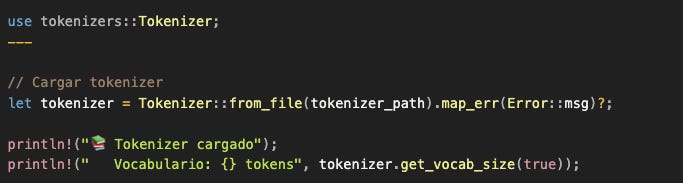
¿Qué contiene ese archivo tokenizer.json?
Tres cosas fundamentales:
El vocabulario completo (típicamente 50k-200k tokens)
Cada token tiene un ID numérico
{ "hello": 15043, "world": 1917, "Par": 4270, ... }
El algoritmo de tokenización (BPE, WordPiece, etc.)
Cómo dividir texto nuevo en tokens del vocabulario
"París"→["Par", "ís"](si “París” completo no existe)
Tokens especiales
<|im_start|>,<|im_end|>: Delimitadores de mensajes</s>,<|endoftext|>: Señales de fin de secuenciaEstos tienen significado especial para el modelo
¿Por qué necesitamos el vocabulario completo en memoria?
Porque vamos a hacer dos operaciones constantemente:
Encode:
"Hola mundo"→[8240, 38821](antes de enviar al modelo)Decode:
[4270]→"Par"(cada token que el modelo genera, lo mostramos)
El decode especialmente tiene que ser instantáneo porque lo hacemos en el loop de generación. Si tardara aunque sea 10ms, el streaming se sentiría entrecortado.
Obtener el token de fin de secuencia:
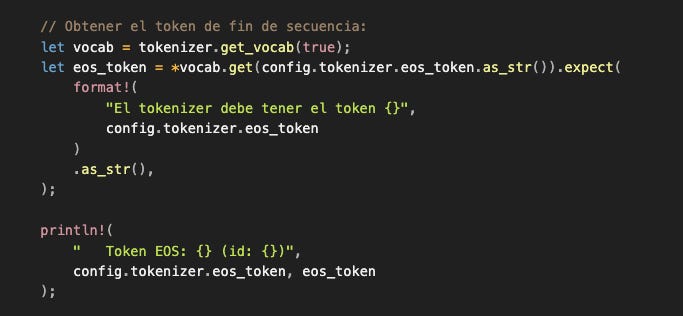
Este token es crítico para el loop de generación. Cuando el modelo genera este token, significa “terminé mi respuesta, no generes más”. Es la condición de parada natural (además del límite de max_length).
¿Por qué lo buscamos en el vocabulario en lugar de hardcodearlo?
Porque distintos modelos usan diferentes tokens de fin. Al tenerlo en el config, cuando cambias de modelo solo actualizas el YAML y el código sigue funcionando. Si el token no existe en el vocabulario, el programa falla inmediatamente con un error claro en lugar de generar tokens infinitamente.
Cargar el modelo (aquí se pone interesante)
Ahora viene la parte heavy: cargar 4 mil millones de parámetros en memoria.
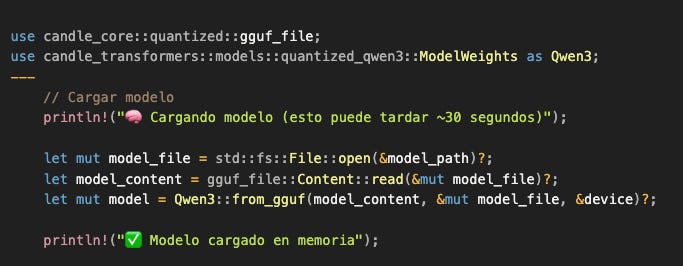
¿Qué está pasando en gguf_file::Content::read()?
GGUF (GPT-Generated Unified Format) es un formato de archivo diseñado específicamente para modelos quantizados. Contiene:
Metadata del modelo:
Arquitectura (transformer, número de capas, dimensiones)
Configuración (attention heads, hidden size, vocab size)
Información de quantización (qué capas usan qué precisión)
Los pesos del modelo:
~4 mil millones de números
Quantizados a 4-bit (cada número ocupa 4 bits en lugar de 32)
Organizados por capa (embeddings, attention, MLP, etc.)
¿Por qué el archivo es “solo” 2.5GB si tiene 4B parámetros?
Matemática simple:
Sin quantización (float32): 4B parámetros × 4 bytes = 16 GB
Con Q4 (4-bit): 4B parámetros × 0.5 bytes = 2 GB
Overhead de metadata: +0.5 GB ≈ 2.5 GB total
La quantización comprime el modelo sin reentrenarlo. Cada peso float32 se convierte en un número de 4-bit usando un algoritmo inteligente que minimiza la pérdida de precisión.
¿Qué significa “cargar en device“?
Cuando ejecutamos:

Candle está:
Leyendo los pesos del archivo
Desquantizando dinámicamente (convirtiendo de 4-bit a float cuando es necesario)
Copiando los tensors al device especificado (GPU o CPU)
Inicializando estructuras internas (buffers, KV cache placeholders, etc.)
Si tu device es Metal o CUDA, esto significa que estás moviendo ~2.5GB de datos a memoria de GPU. Por eso tarda ~30 segundos la primera vez.
Estructura interna del modelo (vista de alto nivel)
El modelo que acabamos de cargar es un transformer con 32 capas secuenciales. No vamos a entrar en los detalles de cada capa ahora (eso merece su propio artículo profundo), pero conceptualmente:
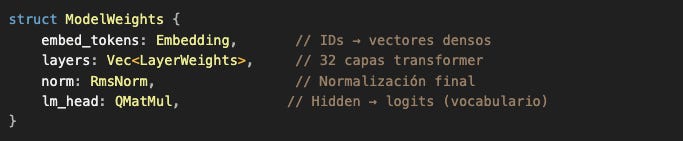
El flujo simplificado:

Cada capa contiene:
Attention: para relacionar tokens entre sí
MLP: red feed-forward que transforma representaciones
Normalizaciones y residual connections
Lo importante que debes saber por ahora:
El modelo es una función matemática gigante: toma tokens de entrada, devuelve logits de salida
Es determinístico: mismo input → mismo output (siempre)
Tiene estado interno (KV cache) que permite procesar tokens incrementalmente
El forward pass es la operación cara (por eso importa tanto el device)
¿Qué es el KV cache?
Durante attention, el modelo calcula Keys y Values de cada token. Sin cache:
Iteración 1: calcular K/V de tokens [0..10]
Iteración 2: calcular K/V de tokens [0..11] (recalculamos 0-10 otra vez)
Iteración 3: calcular K/V de tokens [0..12] (recalculamos todo de nuevo)
Con KV cache:
Iteración 1: calcular K/V de tokens [0..10], guardar en cache
Iteración 2: calcular K/V solo del token 11, concatenar con cache
Iteración 3: calcular K/V solo del token 12, concatenar con cache
Esto hace la generación ~45x más rápida. Por eso llamamos al primer forward pass con todos los tokens “prefill” (llenar el cache), y las siguientes iteraciones son “decode” (usar el cache).
El KV cache vive dentro del modelo, por eso cuando queremos generar desde cero con diferentes configuraciones (como en el experimento de haikus), cargamos el modelo de nuevo para resetear el cache.
En un artículo futuro vamos a entrar en detalle en cómo funcionan attention, RoPE, GQA, y toda la arquitectura interna del transformer. Por ahora, tratémoslo como una caja que clasifica tokens eficientemente.
Componente 5: El loop autoregresivo (donde todo cobra vida)
Todas las piezas están en su lugar. Ahora viene el momento de generar texto. Pero antes de escribir el loop, necesitamos entender algo fundamental que cambia por completo cómo pensamos sobre estos modelos.
La revelación de 2022 y por qué todos los modelos son autocompletadores
Déjame llevarte a un momento histórico en la evolución de los LLMs.
En 2020, OpenAI lanzó GPT-3. Era impresionante: 175 mil millones de parámetros, capaz de generar texto coherente. Pero tenía un problema: solo completaba texto.
Le dabas:

Y completaba:

Funcionaba. Pero si intentabas tener una conversación:

El modelo completaba con cualquier cosa. A veces respondía correctamente, a veces seguía haciendo preguntas, a veces generaba basura. No entendía el concepto de “rol” o “conversación”.
Pero algunos usuarios empezaron a experimentar. ¿Qué pasaba si estructurabas el input como una conversación completa?

El modelo completaba coherentemente. Seguía el patrón. Asumía el rol de “Assistant”. Respondía como si fuera parte de una conversación.
La revelación: El modelo no necesitaba “entender” conversaciones. Solo necesitaba ver suficientes ejemplos de conversaciones estructuradas durante su entrenamiento para poder completar ese patrón.
De GPT-3 a GPT-3.5: el nacimiento de los modelos instruct
OpenAI se dio cuenta de algo poderoso: si el modelo podía aprender patrones conversacionales por accidente, ¿qué pasaría si lo entrenáramos intencionalmente con millones de conversaciones estructuradas?
Y así nacieron los modelos instruct.
Tomaron GPT-3 y lo entrenaron adicionalmente (fine-tuning) con datasets que lucían así:
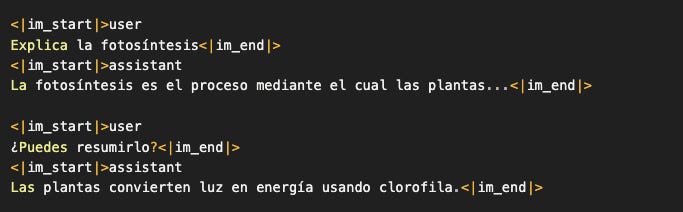
Los tokens especiales <|im_start|>, <|im_end|>, y las etiquetas user/assistant no son mágicos. Son simplemente marcadores en el texto que ayudan al modelo a distinguir:
Quién está hablando
Dónde empieza y termina cada mensaje
Qué rol debe asumir cuando autocompleta
El resultado fue GPT-3.5 (2022), el primer modelo detrás de ChatGPT. Y el mundo cambió.
La verdad detrás del telón: nada cambió arquitecturalmente
GPT-3 (base model) y GPT-3.5 (instruct) tienen la misma arquitectura. El mismo número de capas. Los mismos mecanismos de attention. El mismo objetivo de entrenamiento: predecir el siguiente token.
Lo único que cambió:
El dataset de fine-tuning: conversaciones estructuradas en lugar de texto crudo de internet
El formato de entrada: usar templates con roles y tokens especiales
Nuestra interpretación de la salida: tratamos la respuesta como “lo que el assistant diría” en lugar de “cualquier continuación posible del texto”
El modelo sigue siendo un autocompletador. No “entiende” que está en una conversación. No “sabe” que es un assistant. Solo aprendió que cuando ve el patrón:

… debe completar con texto que estadísticamente se parece a "respuestas de assistant" que vio en su entrenamiento.
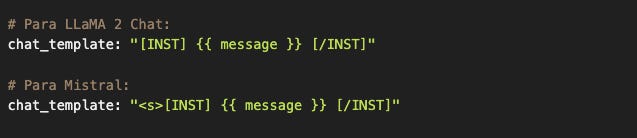
Chat templates: el formato que hace posible el truco
Cada modelo instruct fue entrenado con su propio formato de conversación:
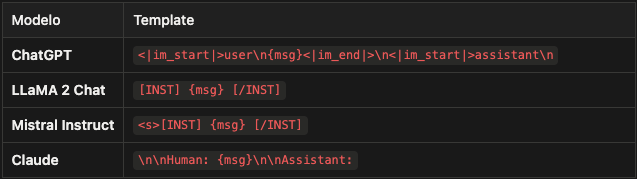
Si usas el formato incorrecto, el modelo genera basura. No porque “no entienda”, sino porque nunca vio ese patrón durante entrenamiento. Es como pedirle a alguien que complete una frase en un idioma que no conoce.
Por eso el chat_template está en la configuración del tokenizer: está acoplado al vocabulario y al entrenamiento del modelo. Cuando cambias de modelo, cambias el template.
Nuestra configuración:
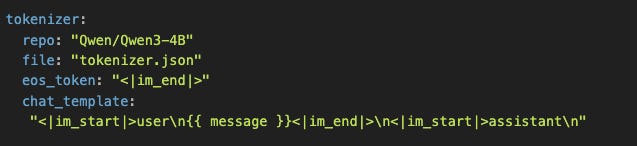
El template usa {{ message }} como placeholder (sintaxis Jinja2). Vamos a reemplazarlo con el mensaje real del usuario.
Function calling: el mismo truco, diferente dataset
Antes de continuar con el código, una nota sobre “function calling” (que veremos en artículos futuros):
Cuando un modelo como GPT-4 “llama funciones”, no está ejecutando nada. Solo está generando texto con un formato específico:

¿Por qué genera ese JSON? Porque fue entrenado con ejemplos donde:
El user describe una intención
El assistant responde con JSON estructurado representando una función
El modelo sigue autocompletando. Solo que ahora autocompleta con “llamadas a funciones” porque eso es lo que vio en su dataset de fine-tuning.
Nosotros (el sistema de inferencia) somos quienes:
Parseamos ese JSON
Ejecutamos la función real
Devolvemos el resultado al modelo como parte del contexto
El modelo autocompleta la siguiente parte de la conversación
El modelo nunca ejecutó nada. Solo generó texto que representa la intención de ejecutar algo.
Esta comprensión es fundamental: los modelos LLM son autocompletadores sofisticados con formatos de entrada/salida cuidadosamente diseñados. Todo lo demás (conversaciones, tools, agentes) es orquestación que construimos alrededor de esa capacidad básica.
Aplicar el chat template en código
Ahora que entendemos por qué necesitamos templates, implementémoslo:
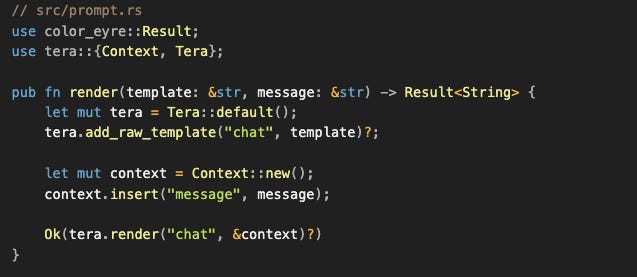
Uso:
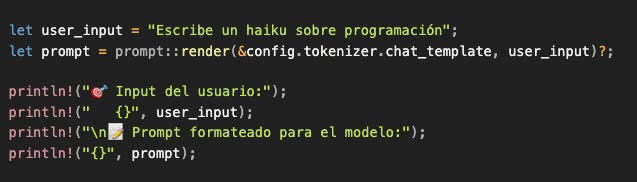
Output:
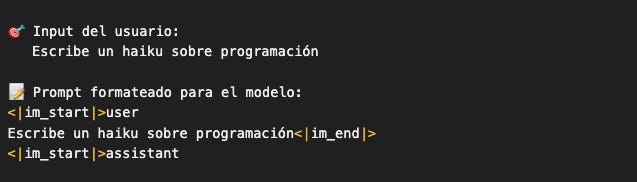
Detalles importantes:
El prompt termina con
assistant\\npero no cierra con<|im_end|>Esto es intencional: dejamos el “turno” del assistant abierto
El modelo va a autocompletar esa parte
Cuando el modelo termine, él mismo generará el token
<|im_end|>
Si cambias de modelo, solo actualizas el config.yaml:
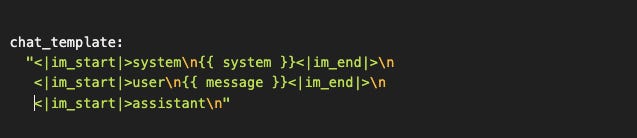
Templates más complejos pueden incluir system prompts:
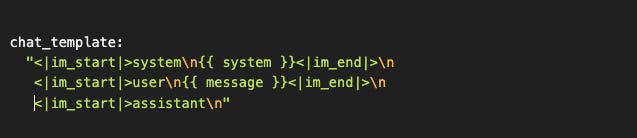
Ahora sí, con el prompt correctamente formateado, podemos tokenizar y entrar al loop.
Tokenizar el prompt formateado
Ahora convertimos ese string estructurado en la secuencia de números que el modelo puede procesar:
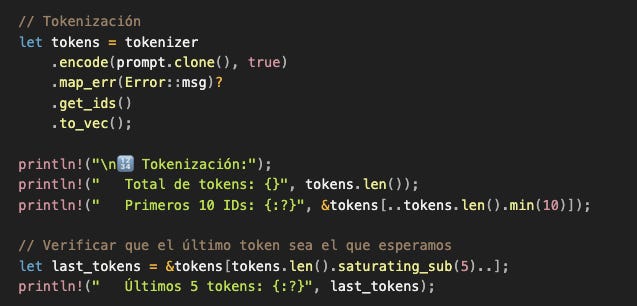
Output esperado:

Esos números son completamente opacos para nosotros, pero para el modelo son el input real. Cada número mapea a un pedazo de texto del vocabulario:
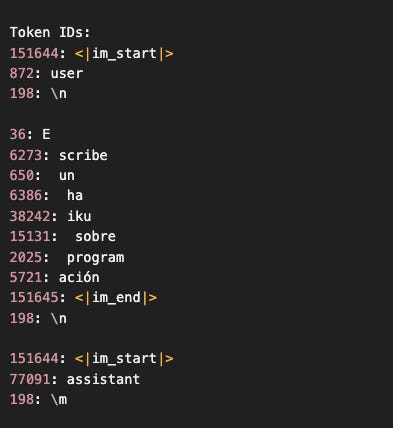
Iteración 0: Prefill (llenar el KV cache)
Ahora viene el primer forward pass. Esta iteración es especial por tres razones:
Procesamos todos los tokens del prompt (no solo uno)
El modelo llena su KV cache por primera vez
Es la más lenta (más tokens = más cómputo)
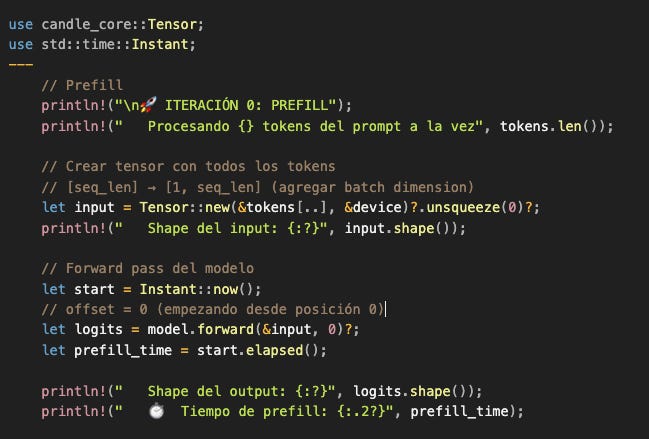
Output esperado:
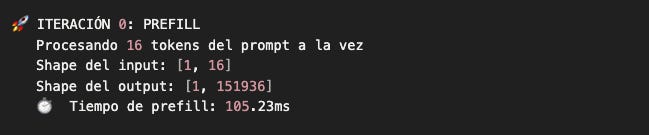
¿Qué acabó de pasar?
El modelo:
Convirtió cada token ID en un embedding (vector de 3584 dimensiones)
Procesó esos 16 embeddings a través de 32 capas transformer
En cada capa:
Calculó Queries, Keys, y Values para attention
Guardó K y V en el KV cache (esto es lo importante)
Aplicó attention entre todos los tokens
Procesó a través del MLP
Retornó logits para cada posición:
[1, 16, 151936]1: batch size
16: una predicción por cada posición de la secuencia
151936: un score por cada token del vocabulario
Ahora el KV cache está lleno con las Keys y Values de estos 16 tokens. En las siguientes iteraciones, solo tendremos que calcular K/V del nuevo token y concatenarlos con el cache.
¿Por qué nuestro shape es de [1, 151936]?
Aquí está el detalle que revela cómo funcionan estos modelos bajo el capó.
La arquitectura transformer base retorna logits para CADA posición de la secuencia.
Si procesamos 16 tokens, internamente el modelo genera:

Donde:
1: batch size
16: una predicción para cada posición
151936: logits para cada token del vocabulario
¿Qué significa “una predicción para cada posición”?
Que el modelo está prediciendo:

Ejemplo concreto con nuestro prompt:
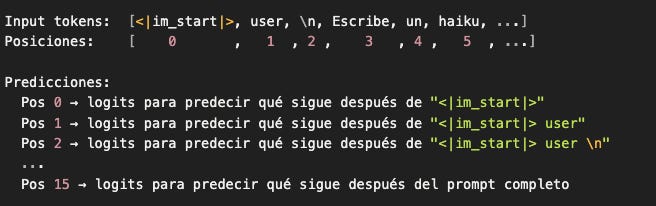
¿Por qué el modelo hace esto?
Porque durante el entrenamiento, esto es extremadamente eficiente. Con un solo forward pass del modelo, obtienes 16 predicciones que puedes comparar con los 16 tokens correctos y calcular la pérdida (loss).
Si tuvieras que hacer forward passes separados para cada posición, entrenar sería 16x más lento.
Pero durante inferencia (generación de texto), solo nos importa UNA predicción: la última.
No necesitamos saber:
¿Qué viene después de
<|im_start|>? (Ya sabemos:user, está en el prompt)¿Qué viene después de
<|im_start|> user? (Ya sabemos:\\n, está en el prompt)...
Solo necesitamos:
¿Qué viene después del prompt completo? ← Esto es lo que vamos a generar
Por eso, de esos [1, 16, 151936] logits, solo usamos la última posición:
La optimización de Candle: extracción automática
Generar [1, 16, 151936] y luego descartar 15/16 del resultado es desperdicio puro. Estamos calculando millones de valores que nunca vamos a usar.
Por eso, la implementación de Candle ya optimiza esto dentro de model.forward():
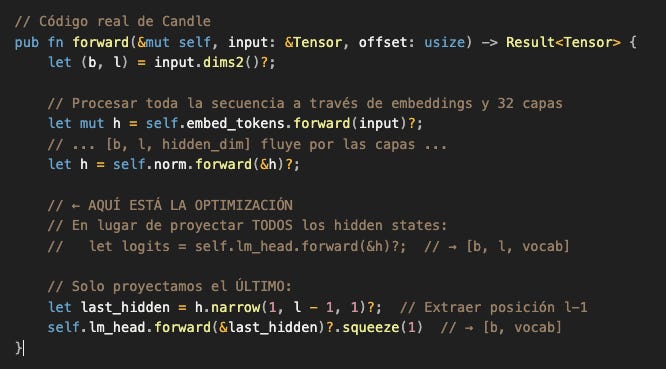
¿Por qué no siempre hacemos esto?
Durante entrenamiento, necesitamos los logits de todas las posiciones para calcular el loss. Así que ahí sí generamos [batch, seq_len, vocab] completo.
Durante inferencia, solo necesitamos la última posición, así que Candle optimiza automáticamente.
Esta es la belleza de una implementación bien pensada: el mismo código del modelo se comporta diferente según el contexto de uso, optimizando cada caso.
Ventana de contexto y otras implicaciones
Este detalle de que el modelo genera logits para todas las posiciones no es solo una curiosidad de implementación. Tiene implicaciones directas en varios conceptos que seguramente has escuchado:
1. La famosa “ventana de contexto” (context window)
Cuando ves que GPT-4 tiene “128k tokens de contexto” o que Qwen3-4B tiene “32k tokens”, eso significa:
El modelo puede procesar hasta N tokens en un solo forward pass y generar predicciones para todas esas posiciones simultáneamente.
Si procesas 32,000 tokens (el límite de Qwen3):
Input:
[1, 32000]Output interno:
[1, 32000, 151936]Memoria de activaciones: gigantesca
Por eso los modelos tienen límites de contexto: la memoria y el cómputo escalan cuadráticamente con la longitud de secuencia debido al attention.
Attention calcula similitud entre cada par de tokens:
100 tokens → ~10,000 comparaciones
1,000 tokens → ~1,000,000 comparaciones
32,000 tokens → ~1,024,000,000 comparaciones
Por eso modelos con contextos largos necesitan técnicas como:
Flash Attention (optimización de memoria)
Grouped Query Attention (reducir Keys/Values)
Sparse Attention (no atender a todos los tokens)
2. Fill-in-the-middle (FIM)
¿Alguna vez usaste GitHub Copilot y viste que “completa en medio del código”? No está usando un modelo especial.
El modelo genera logits para cada posición. Si le das:

El modelo genera predicciones para:
Posición 0 (después de
def)Posición 1 (después de
def calculate_total)...
Posición N (después del cursor) ← Usas esta
Posición N+1 (después de
return)...
Puedes extraer logits de cualquier posición, no solo la última. Eso permite “completar en medio”.
3. Logprobs en APIs (como OpenAI)
Cuando pides logprobs=true en la API de OpenAI, te retornan algo como:
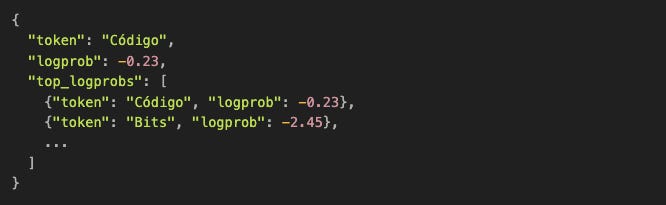
¿De dónde salen esos valores? De los logits de esa posición.
El modelo ya calculó [vocab_size] scores. Solo están exponiendo esa información que normalmente descartan después del sampling.
4. Perplexity (métrica de calidad)
Perplexity mide “qué tan sorprendido está el modelo con el texto real”.
Para calcularlo necesitas los logits de todas las posiciones, comparando la predicción con el token real que sigue.

Por eso las herramientas de evaluación de modelos procesan texto completo de una sola vez: obtienen [1, seq_len, vocab] y calculan perplexity sobre toda la secuencia.
5. “Cosas raras” que puedes hacer
Como el modelo genera predicciones para cada posición, puedes:
a) Detectar “confianza” por token:
Si los logits de una posición tienen un pico claro → modelo confiado
Si están dispersos → modelo inseguro
Útil para detectar alucinaciones
b) Forzar tokens en posiciones específicas:
“Quiero que en la posición 5 generes exactamente ‘Python’”
Manipulas los logits de esa posición antes del sampling
Útil para control fino de generación
c) Edición especulativa:
Generas N tokens alternativos para la misma posición
Evalúas cuál es mejor según algún criterio
“Beam search” es una variante de esto
d) Parallel decoding (técnicas experimentales):
Algunas investigaciones intentan generar múltiples tokens a la vez
Usan las predicciones intermedias del modelo
Trading accuracy por velocidad
Por qué esto importa para ti ahora
Entender que el modelo genera [1, seq_len, vocab] internamente te permite:
Comprender limitaciones de memoria: Por qué no puedes procesar contextos infinitos
Entender tradeoffs de velocidad: Por qué prefill es más lento que decode
Anticipar optimizaciones: Por qué KV cache, Flash Attention, y quantization importan tanto
Prepararte para técnicas avanzadas: Logits manipulation, controlled generation, etc.
Por ahora, Candle nos simplifica la vida retornando solo [1, vocab]. Pero en futuros artículos vamos a exponer esos logits completos para hacer cosas más interesantes.
El transformer es más flexible de lo que parece. La generación autoregresiva simple (un token a la vez) es solo una forma de usarlo.
Samplear el primer token generado
Los logits están listos: [1, 151936]. Ahora el sistema de inferencia toma control. El modelo ya hizo su trabajo (clasificar). Ahora nosotros decidimos qué token elegir.
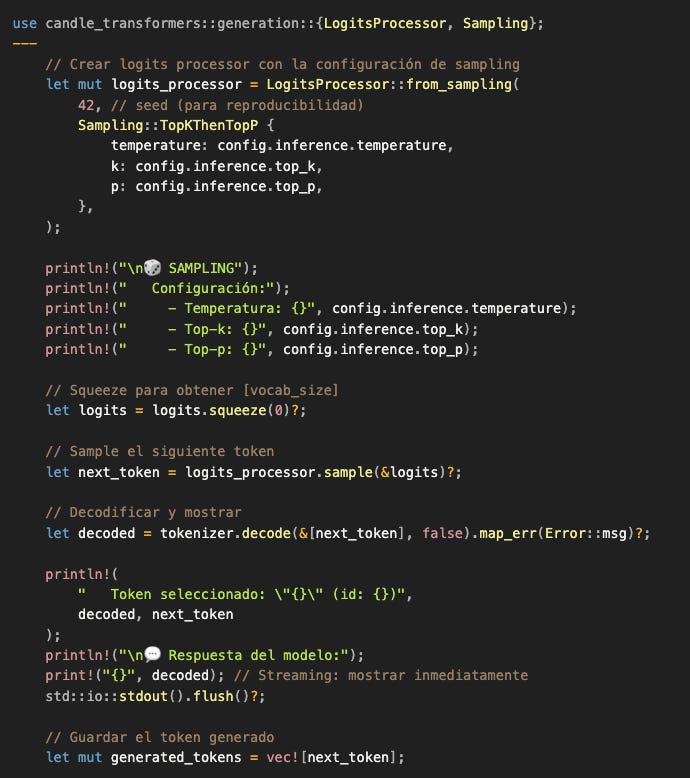
Output:
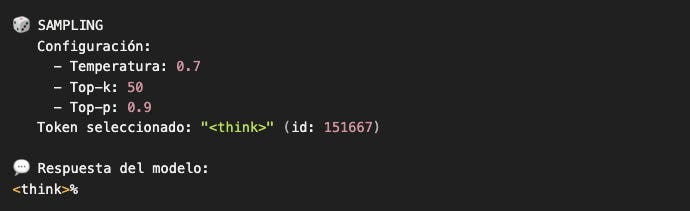
El modelo está “pensando”... ¿o no?
El modelo generó <think> como su primer token. ¿Qué significa esto?
Spoiler: No significa que el modelo esté “pensando”. Significa que vio suficientes ejemplos de conversaciones que empiezan con <think> durante su entrenamiento.
Pero antes de que pienses que estoy siendo reductivo, déjame contarte la historia fascinante detrás de este token. Porque esto conecta directamente con uno de los desarrollos más importantes en LLMs de los últimos años: Chain-of-Thought (CoT).
La historia del “pensamiento” en LLMs
2022: El descubrimiento de Chain-of-Thought
Investigadores de Google descubrieron algo sorprendente. Si le pedías a un LLM resolver un problema matemático así:

El modelo fallaba frecuentemente. Pero si cambiabas el prompt a:

El modelo generaba:

Y la respuesta era correcta con mucha más frecuencia.
¿Por qué?
Porque al forzar al modelo a “pensar en voz alta” (generar razonamiento intermedio), le das más tokens de contexto antes de llegar a la respuesta. Cada token generado puede informar al siguiente.
Es como la diferencia entre:
“¿Cuánto es 357 × 23?” → respuesta directa (difícil)
“Calculemos 357 × 23 paso a paso: primero 357 × 20 = ...” → razonamiento explícito (más fácil)
El modelo sigue autocompletando. Pero autocompleta un patrón más fácil de seguir.
2023-2024: Codificar CoT en el entrenamiento
Lo que empezó como un truco de prompting (agregar “piensa paso a paso” al prompt) evolucionó.
Los creadores de modelos se dieron cuenta: “Si este patrón funciona tan bien, ¿por qué no entrenamos al modelo específicamente para hacerlo?”
Así nacieron datasets de entrenamiento como:
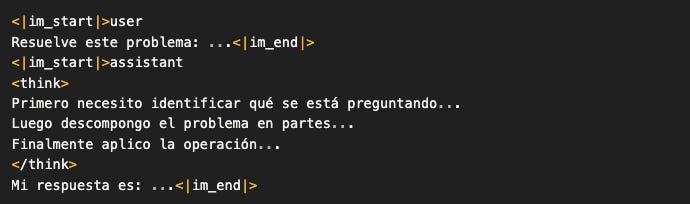
El token <think> se convirtió en un marcador especial que le indica al modelo:
“Aquí empieza tu razonamiento interno antes de dar la respuesta final”
Y el modelo aprendió ese patrón. Ahora, cuando ve ciertas preguntas, automáticamente genera <think> y elabora razonamiento antes de responder.
¿Entonces el modelo está “pensando”?
No. El modelo sigue autocompletando.
Lo que cambió:
El dataset de entrenamiento incluye ejemplos con razonamiento explícito
El modelo aprendió que después de ciertos prompts, generar
<think>es estadísticamente probableUna vez que genera
<think>, continúa autocompletando con el patrón de razonamiento que vio en entrenamiento
Es el mismo proceso que vimos desde 2020: predecir el siguiente token basándose en lo que vio antes.
La “magia” es que ese patrón resulta ser útil. Generar razonamiento intermedio mejora las respuestas finales, no porque el modelo “entienda” que está razonando, sino porque más tokens de contexto = más información para predecir el siguiente token.
El marketing vs la realidad
Verás documentación que dice:
La realidad técnica:
El modelo genera tokens siguiendo patrones de su entrenamiento. Si esos patrones incluyen <think>, los genera. Si incluyen razonamientos paso a paso, los genera. Pero no hay un “modo” especial. No hay un switch que activa “pensamiento”.
Solo hay:
Tokens especiales (
<think>,<reasoning>, etc.)Datasets de entrenamiento que contienen esos patrones
Un modelo que aprendió a autocompletar esos patrones
¿Eso lo hace menos impresionante?
Para nada. Lo hace más impresionante porque demuestra que:
La arquitectura simple (autocompletar) es suficientemente flexible
El diseño inteligente de datasets puede cambiar comportamientos dramáticamente
No necesitas “módulos de razonamiento” especiales en la arquitectura
Es un comportamiento emergente puro: comportamiento complejo surge de reglas simples aplicadas a datos bien diseñados.
Para nuestro caso: desactivar el modo “thinking”
El modelo Qwen3 fue entrenado con ejemplos de <think>. Por defecto, para ciertas preguntas, generará razonamiento explícito.
Eso está bien para problemas complejos. Pero para nuestro caso (generar un haiku), queremos la respuesta directa.
¿Cómo lo controlamos?
Aquí es donde entender que el modelo solo autocompleta te da superpoderes.
La mayoría de la gente haría esto:
Agregar más y más instrucciones en el system message, rogándole al modelo que no haga algo.
Esto es tratar al modelo como si fuera un humano rebelde que necesita instrucciones claras.
Pero recuerda: el modelo no lee instrucciones. El modelo autocompleta patrones.
El approach correcto: pensar como un autocompletador
Si el modelo está generando:
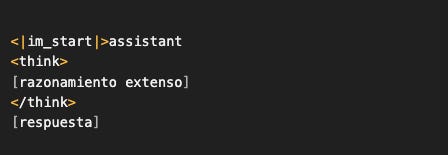
Es porque durante entrenamiento vio ese patrón miles de veces. Estadísticamente, después de <|im_start|>assistant\n, generar <think> es probable.
¿Cómo cambias eso?
No le pides que no lo haga. Le muestras que ya lo hizo.
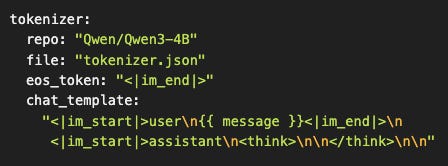
¿Qué acabamos de hacer?
Le dimos al modelo un prompt que ya incluye el bloque de pensamiento... vacío.
Desde la perspectiva del modelo:
“Ya generé <think>, ya lo cerré con </think>. ¿Qué sigue en el patrón que vi durante entrenamiento? Ah sí, la respuesta actual.”
Y empieza a generar la respuesta directamente.
Por qué esto funciona (y la otra solución no)
El problema con agregar instrucciones:

El modelo procesa esto como contexto, pero no cambia fundamentalmente la distribución de probabilidad del siguiente token.
Si durante entrenamiento vio:
10,000 ejemplos que empiezan con
<think>después deassistant\n500 ejemplos con instrucciones de “no uses think”
La probabilidad de generar <think> sigue siendo alta porque los patrones de entrenamiento dominan.
El approach de autocompletado cambia estructuralmente lo que el modelo está autocompletando. Ya no está en la posición de “¿empiezo a pensar?”. Está en la posición de “ya pensé (vacío), ¿qué sigue?”. Y lo que sigue, según los patrones de entrenamiento, es la respuesta.
La lección profunda sobre prompting
Cuando ves prompts gigantes como:
You are an expert assistant. Always respond in JSON format. Never use markdown. Do not include explanations. Just the JSON. Please. I'm begging you.
La persona que escribió eso está luchando contra el modelo. Está tratándolo como un humano terco que necesita instrucciones más claras.
Pero el modelo no obedece instrucciones. El modelo autocompleta patrones.
Si quieres JSON, no le pidas JSON. Empieza el JSON por él:
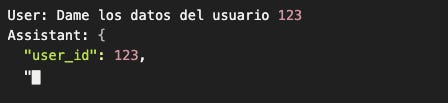
El modelo autocompleta el JSON porque ya está dentro de un patrón de JSON.
Si quieres una lista numerada:

El modelo autocompleta 1. [idea] porque ya iniciaste el patrón.
En nuestro caso no le pedimos que no piense. Le mostramos que ya pensó (y no encontró nada que decir).
Es como si alguien te pregunta:
“¿Qué opinas?”
vs
“Después de pensarlo bien... [pausa vacía] ...¿qué opinas?”
En el segundo caso, tu respuesta sería diferente. Ya “pensaste” (aunque no dijiste nada en esa pausa). Ahora solo falta la conclusión.
Ejecutando con el template actualizado
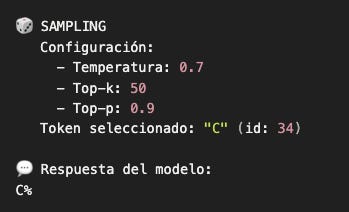
El modelo saltó directamente a la respuesta. No porque “apagamos su pensamiento”, sino porque cambiamos qué está autocompletando.
El patrón general: guiar, no instruir
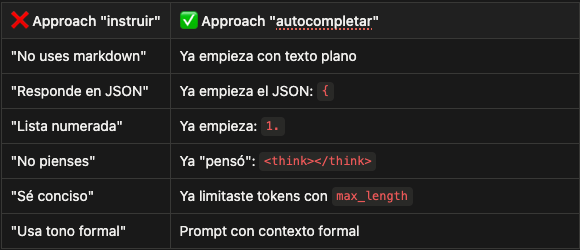
El modelo autocompleta. Si quieres que genere X, ponlo en una posición donde autocompletar X sea lo más probable estadísticamente.
Esto no es “hackear” el modelo. Es entender cómo funciona y trabajar con su arquitectura en lugar de contra ella.
Bonus: cuando SÍ quieres el thinking
Para problemas complejos, el thinking es valioso. En ese caso, template sin modificar:
"<|im_start|>user\n{{ message }}<|im_end|>\n<|im_start|>assistant\n"
Y el modelo genera:
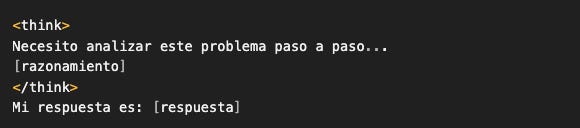
Puedes parsear el thinking y la respuesta separadamente. Útil para:
Debug (ver “por qué” el modelo respondió así)
Chain-of-thought explícito
Validación (si el razonamiento tiene sentido)
Pero para haikus, queremos directo al grano. Por eso el template modificado.
Un resumen antes de continuar:
Principio fundamental: Los LLMs son autocompletadores sofisticados, no seres pensantes que obedecen órdenes.
Corolario práctico: Para controlar el output, modifica qué están autocompletando, no qué les pides que hagan.
Aplicación: En lugar de “no uses <think>“, mostramos que <think></think> ya ocurrió (vacío) y logramos el comportamiento esperado.
Esto es prompt engineering real: entender el mecanismo subyacente y aprovecharlo.
En este punto tal vez deberías ir a tomarte un café (o dos).
Componente 5.1: El loop autoregresivo (después del prefill)
Ya hicimos el trabajo pesado:
✅ Procesamos todo el prompt (16 tokens)
✅ Llenamos el KV cache
✅ Generamos y mostramos el primer token
Ahora viene la parte más satisfactoria: ver al modelo generar texto token por token en tiempo real.
El loop es conceptualmente simple:
Toma el último token generado
Haz forward pass (solo 1 token, usando KV cache)
Sample el siguiente token
Muéstralo inmediatamente (streaming)
¿Es EOS? → termina. ¿No? → repite
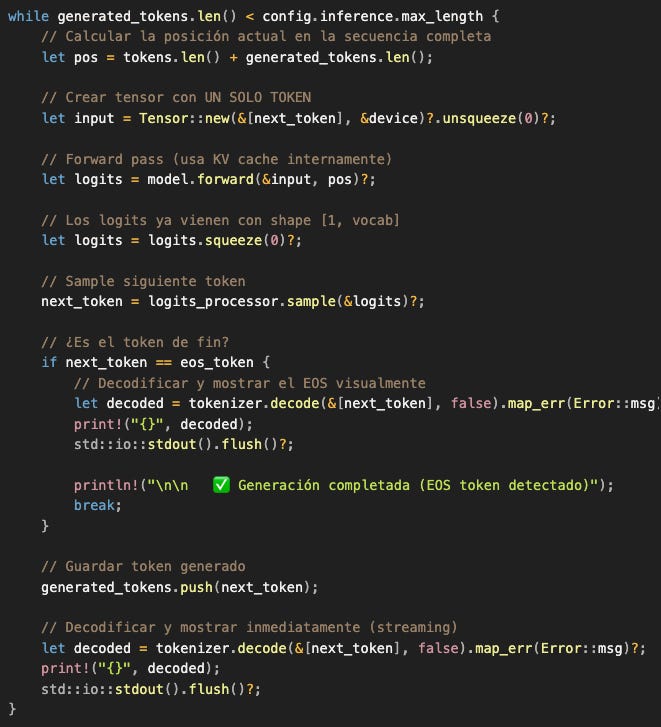
Output esperado (con nuestro haiku):
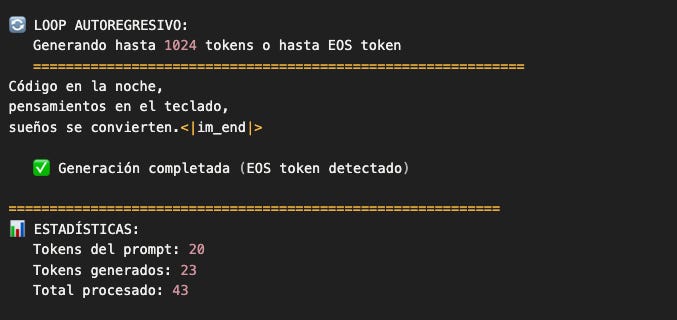
Anatomía del loop: cada pieza importa
1. El parámetro pos (posición absoluta):

Este número le dice al modelo “estás en la posición N de la secuencia completa desde el inicio”.
¿Por qué importa?
RoPE (Rotary Position Embeddings) codifica información posicional aplicando rotaciones a los vectores de attention. Estas rotaciones dependen de la posición absoluta del token en la secuencia.
Sin pos correcto:
El modelo perdería noción de “dónde está”
Las relaciones posicionales entre tokens se romperían
Attention no sabría qué tokens están “cerca” vs “lejos”
Ejemplo de progresión:

Cada token generado se agrega al final de la secuencia, extendiendo la posición.
2. Input de un solo token:

Contrasta esto con el prefill:

¿Por qué esta diferencia cambia todo?
Porque el modelo usa KV cache. Veamos qué pasa internamente:
Sin KV cache (hipotético, ineficiente):

Trabajo total: 17 + 18 + 19 + ... = O(n²) operaciones.
Con KV cache (lo que realmente pasa):

Trabajo total: 16 + 1 + 1 + 1 + ... = O(n) operaciones.
Dentro de AttentionWeights::forward() (del código de Candle):
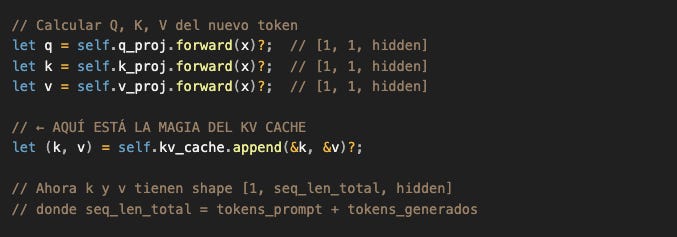
El cache concatena el nuevo K/V con todos los anteriores sin recalcular nada.
Por eso el decode es ~10-20x más rápido que el prefill.
3. Tiempos de generación (lo que verás en tu máquina):
En Metal (M1 Pro):
Prefill (16 tokens): ~80-120ms
Decode (por token): ~4-8ms
Speedup: ~15-20x
En CUDA (RTX 3080):
Prefill (16 tokens): ~20-40ms
Decode (por token): ~2-4ms
Speedup: ~10-15x
En CPU (Intel i7):
Prefill (16 tokens): ~800-1200ms
Decode (por token): ~60-120ms
Speedup: ~10-15x
¿Por qué el speedup es similar en CPU y GPU?
Porque el KV cache reduce el número de operaciones, no solo el tiempo por operación. Es una optimización algorítmica, no solo de hardware.
4. Streaming en tiempo real:

Estos dos comandos son los responsables de que veas el texto "fluyendo" como en ChatGPT.
¿Qué hace flush()?
Por defecto, Rust (y la mayoría de lenguajes) bufferiza la salida:
Guardas varios prints en memoria
Los envía al terminal de una sola vez cuando el buffer se llena o el programa termina
Con flush():
Fuerzas que el texto aparezca inmediatamente en el terminal
Cada token se muestra en cuanto se genera
Esta es la diferencia entre un sistema que se siente “responsive” y uno que parece congelado.
Las APIs de OpenAI, Anthropic, etc. hacen lo mismo: Server-Sent Events (SSE) que envían cada token al cliente inmediatamente.
5. Condiciones de parada:
a) EOS token (parada natural):

Cuando el modelo genera <|im_end|> (token ID 151645 en Qwen3), está diciendo:
“Completé mi mensaje de assistant. No tengo más que decir.”
Esta es la parada correcta y natural. El modelo aprendió durante entrenamiento que después de responder, debe generar este token.
b) max_length (parada forzada):

Si llegas aquí, algo pasó:
El prompt era muy ambiguo y el modelo “se perdió”
La temperatura era muy alta y generó basura sin fin
El modelo está en un loop (raro pero posible)
El EOS token ID está mal configurado
En producción querrías:
Logging de cuándo esto ocurre
Alertas si pasa con frecuencia
Análisis post-mortem del prompt que causó esto
c) Otras paradas posibles (no implementadas aquí):
Timeout por tiempo: “Si pasan 10 segundos, para”
Stop sequences: “Si generas ‘\n\n’, para” (útil para respuestas cortas)
Logit threshold: “Si la probabilidad del mejor token < 0.1, para” (modelo muy inseguro)
Veremos estos en artículos futuros sobre control de generación.
Lo que acabas de ejecutar
Este loop de ~30 líneas es el corazón de todo sistema de generación de texto:
ChatGPT ejecuta este loop (con optimizaciones adicionales)
Claude ejecuta este loop
GitHub Copilot ejecuta este loop
Cualquier chatbot LLM ejecuta este loop
La diferencia es escala y optimizaciones:
Ellos tienen múltiples GPUs
Batch generation (procesar múltiples usuarios en paralelo)
Speculative decoding (intentar generar múltiples tokens a la vez)
Cacheo agresivo de prompts comunes
Serving infrastructure compleja
Pero el algoritmo fundamental es idéntico:

Autocompletado, una iteración a la vez, hasta que el modelo decida parar.
Lo que acabas de leer y construir (y por qué importa más de lo que crees)
Si llegaste hasta aquí y ejecutaste el código, acabas de hacer algo que el 99% de los “AI engineers” nunca hace: construir un sistema de inferencia desde cero.
No copiaste un snippet de la documentación de OpenAI.
No agregaste openai.chat.completions.create() a tu codebase y llamaste a eso “integración de AI”.
No dependes de que un servidor remoto funcione para que tu sistema funcione.
Construiste la máquina completa.
Y ahora que la construiste, ahora que viste cada pieza ensamblandose, algo va a cambiar. Cuando alguien te diga:
“Necesitamos reducir la latencia de nuestro chatbot”
Ya no vas a pensar en “pedirle a OpenAI que sea más rápido”. Piensarás:
¿Estamos usando GPU o CPU?
¿El modelo está quantizado eficientemente?
¿Tenemos KV cache habilitado?
¿Podemos hacer prefill batch y decode por separado?
¿Usamos speculative decoding para secuencias predecibles?
Cuando alguien diga:
“El modelo no está generando el formato que necesitamos”
Ya no cruzarás los dedos y agregarás más instrucciones al system prompt. Pensarás:
¿Estoy guiando el autocompletado o solo pidiendo?
¿Puedo manipular los logits para forzar ciertos tokens?
¿Debería usar un template diferente que ya incluya la estructura?
¿Puedo implementar constrained decoding?
Cuando alguien diga:
“Esto es muy caro, gastamos $10k/mes en la API”
Ya no te encogerás de hombros. Pensarás:
Ese modelo tiene 70B parámetros. ¿Realmente necesitamos tanto?
Un modelo de 4B quantizado cuesta $0 después de la descarga inicial
En 2 meses recuperaría el costo de una GPU usada en eBay
¿Qué parte del problema realmente requiere un modelo gigante?
Esta es la diferencia entre ser un consumidor y ser un ingeniero.
Pero esto es solo el principio
Lo que construimos hoy es la fundación. El sistema básico que funciona. El “Hello World” de AI Engineering, pero uno que realmente entiendes.
Ahora vienen las preguntas interesantes:
Sobre control de generación:
¿Cómo fuerzo al modelo a generar JSON válido siempre?
¿Cómo implemento grammar-based decoding?
¿Cómo hago que el modelo genere código que compila?
Sobre optimización:
¿Cómo implemento speculative decoding?
¿Qué es Flash Attention y por qué debería importarme?
¿Cómo proceso múltiples requests en paralelo (batching)?
Sobre arquitectura:
¿Cómo convierto esto en un servidor HTTP que sirve múltiples usuarios?
¿Cómo implemento un sistema de RAG que usa este modelo?
¿Cómo construyo un agente que puede usar herramientas?
Sobre evaluación:
¿Cómo mido si un modelo es “mejor” que otro para mi caso de uso?
¿Cómo implemento benchmarks automatizados?
¿Cómo detecto cuando el modelo está alucinando?
Cada una de estas preguntas merece su propio artículo. Y las vamos a cubrir todas.
El reto
Aquí está tu homework (y sí, es obligatorio si quieres entender esto de verdad):
Nivel 1: Experimenta con lo que tienes
Cambia
temperaturea 0.0, 0.5, 1.0, 1.5. Genera el mismo haiku 3 veces con cada valor. Observa cómo cambia el output.Modifica
max_lengtha 50 tokens. ¿El modelo respeta el límite o termina antes con EOS?Cambia el prompt a algo completamente diferente: “Explica recursión como si tuviera 5 años”. ¿Cómo se comporta el modelo?
Nivel 2: Modifica el sistema
Agrega un contador que muestre tokens/segundo en tiempo real mientras genera.
Implementa una parada adicional: si el modelo genera “\n\n” (dos newlines), termina la generación.
Guarda los
generated_tokensen un archivo JSON con timestamps de cada token.
Nivel 3: Rompe cosas intencionalmente
¿Qué pasa si usas el chat template de Mistral con el modelo de Qwen? Ejecútalo y observa.
¿Qué pasa si
eos_tokenapunta a un token que no existe en el vocabulario?¿Qué pasa si haces
temperature = 0ytop_k = 1? ¿Es realmente determinístico? Genera 3 veces y compara.
Nivel 4: Construye algo útil
Implementa un sistema que lee un archivo
.txt, lo tokeniza, y calcula cuántos tokens ocupa (útil para estimar costos de APIs).Crea un loop interactivo: el usuario escribe, el modelo responde, el usuario continúa la conversación.
Implementa “thinking mode” opcional: si el user pregunta algo complejo, automáticamente usa el template sin <think></think> prefilled.
Por qué esto importa ahora más que nunca
Estamos en 2026. Los LLMs ya no son “el futuro”. Son el presente. Pero la industria se está bifurcando:
Grupo A: Gente que consume APIs y espera que “OpenAI lo solucione”.
Grupo B: Gente que entiende los fundamentos y puede construir sistemas reales.
El Grupo A va a tener trabajo. El Grupo B va a definir cómo se usa esta tecnología.
Cuando llega un problema que la API no puede resolver, el Grupo A se queda esperando que lancen una feature. El Grupo B abre el repo, lee el paper, implementa la solución, y sigue adelante.
Tú acabas de entrar al Grupo B.
Tienes el código. Tienes el entendimiento. Ahora depende de ti qué construyes con esto.
Lo que viene después
El próximo artículo va a ser sobre control total de generación. Vamos a:
Manipular logits directamente para forzar patrones
Implementar constrained decoding (solo generar tokens válidos según una gramática)
Hacer que el modelo genere JSON perfecto sin “prompt engineering”
Explorar logit biasing, token banning, y otras técnicas de control fino
Después de eso: RAG (Retrieval-Augmented Generation). Cómo construir un sistema que le da al modelo acceso a documentos externos, bases de código, o bases de datos. Sin SDKs. Sin LangChain. Desde cero.
Y luego: Agentes. Cómo construir un sistema que puede usar herramientas, razonar sobre múltiples pasos, y ejecutar tareas complejas. Con el mismo modelo que acabas de cargar.
Cada artículo construye sobre el anterior. Cada artículo agrega una capa de sofisticación sin perder el entendimiento fundamental.
Última palabra
La mayoría del contenido sobre AI que vas a encontrar cae en dos extremos:
Demasiado simple: “Así usas la API de OpenAI” (útil por 5 minutos, luego limitante)
Demasiado académico: Papers con notación matemática impenetrable (interesante, pero no implementable)
Esto que estás leyendo intenta ser el punto medio incómodo: suficientemente profundo para entender qué está pasando, suficientemente práctico para implementar cosas reales.
Si construiste el sistema, si lo ejecutaste, si viste el texto aparecer token por token en tu terminal... ya entendiste más que la mayoría.
Ahora no pares.
Modifica el código. Rómpelo. Arréglalo. Hazlo tuyo.
Porque la próxima vez que alguien te diga “esto lo resuelve un LLM”, ya no vas a pensar en una caja negra mágica.
Vas a pensar en logits, sampling, loops autoregresivos, y KV cache.
Y vas a saber exactamente cómo construirlo.
El código completo está disponible en GitHub. Si construiste algo interesante modificando este sistema, etiquétame en LinkedIn. Quiero ver qué rompiste y qué construiste.
Próximo artículo: “Control Total: Manipulación de Logits y Constrained Decoding” - donde dejamos de pedirle cosas al modelo y empezamos a forzarlo a hacer exactamente lo que queremos.
Nos vemos en el siguiente.